Phương pháp phát hiện dữ liệu bất thường trong giám sát trực tuyến an toàn thông tin tài chính, ngân hàng
Để góp phần phát triển các kỹ thuật giám sát và đảm bảo an toàn |18/10/2022 08:09
Trong bài viết này, chúng tôi đề xuất một thuật toán hai bước sử dụng thuật toán ngưỡng để tiền phân loại và phương pháp phân cụm để xác nhận nhãn của điểm dữ liệu mới nhằm làm giảm tỷ lệ dương tính giả và âm tính giả. Các thí nghiệm được thực hiện trên hai bộ dữ liệu bao gồm một bộ dữ liệu tự sinh và một bộ dữ liệu thực mô tả các giao dịch bằng thẻ tín dụng của khách hàng ở châu Âu.
Tóm tắt: Trong những năm gần đây, nhiều nhà khoa học đã nghiên cứu, mô hình hóa các bài toán chuỗi thời gian thực tế trong lĩnh vực tài chính, ngân hàng và ứng dụng các kỹ thuật học máy thống kê để giải quyết chúng. Trong đó, bài toán phát hiện dữ liệu bất thường trong kịch bản trực tuyến là một trong những bài toán được quan tâm rộng rãi bởi khả năng ứng dụng cao trong các quá trình giám sát, phân tích dữ liệu thu thập được và báo cáo các quan sát bất thường để đảm bảo môi trường vận hành an toàn. Trong kịch bản trực tuyến, mô hình chỉ sử dụng dữ liệu lịch sử và thuật toán phát hiện bất thường cần đảm bảo thời gian thực thi thấp. Phương pháp phổ biến thường được sử dụng là giả định dữ liệu tuân theo phân phối chuẩn và dùng thuật toán ngưỡng để phân loại. Trong bài viết này, chúng tôi đề xuất một thuật toán hai bước sử dụng thuật toán ngưỡng để tiền phân loại và phương pháp phân cụm để xác nhận nhãn của điểm dữ liệu mới nhằm làm giảm tỷ lệ dương tính giả và âm tính giả. Các thí nghiệm được thực hiện trên hai bộ dữ liệu bao gồm một bộ dữ liệu tự sinh và một bộ dữ liệu thực mô tả các giao dịch bằng thẻ tín dụng của khách hàng ở châu Âu. Kết quả thực nghiệm chỉ ra rằng, thuật toán đề xuất làm giảm đáng kể tỷ lệ dương tính giả và âm tính giả so với thuật toán thường hay sử dụng. Mô hình và thuật toán đề xuất có thể được ứng dụng rộng rãi trong các hệ thống giám sát thông tin giúp các ngân hàng, tổ chức tài chính kịp thời phát hiện các cuộc tấn công hoặc gian lận trong sử dụng dịch vụ.
Từ khóa: Phát hiện bất thường, giám sát trực tuyến, gian lận tài chính.
A PROPOSED ABNORMAL DETECTION ALGORITHM FOR MONITORING INFORMATION SECURITY OF BANKING AND FINANCE IN ONLINE SCENARIO
Abstract: Recently, many researchers have studied problems of time series processes in banking and finance sector and applied statistical learning techniques to solve them. In particular, the abnormal detection problem in an online scenario is one of the most widely-studied problems due to its high applicability in information security. In the online scenario, abnormal detection models are required to use only historical data and ensure low execution time. The popular statistical approaches often assumed that data followed a normal distribution and used threshold values for classification. In this paper, we propose a new two-step algorithm for abnormal detection in the online scenario. The first step uses a threshold algorithm to predict a label of a new data point. The second step validates the predicted label by using a clustering method to reduce the false-positive and false-negative rates. Experimental results on an artificial dataset and a real credit card transaction dataset show the efficiency and applicability of the proposed algorithm for information monitoring and abnormal warning in the banking and finance sector.
Hoạt động của ngành tài chính, ngân hàng đóng một vai trò quan trọng trong việc thiết lập sự ổn định tài chính của mỗi quốc gia. Hơn nữa, sự gia tăng dân số, phát triển kinh tế và công nghệ đã đẩy mạnh nhu cầu sử dụng các dịch vụ ngân hàng, tài chính của người dân một cách an toàn, hiệu quả. Do đó, những người ra quyết định trong ngành này rất cần các công cụ phân tích dữ liệu lớn để dự đoán, phân loại thông tin, kịp thời đưa ra các cảnh báo khi dữ liệu thu thập được có dấu hiệu bất thường. Trong những năm gần đây, nhiều nhà nghiên cứu đã mô hình hóa các bài toán chuỗi thời gian thực tế trong lĩnh vực tài chính, ngân hàng và ứng dụng các kỹ thuật học máy để giải quyết chúng. Trong đó, bài toán phát hiện dữ liệu bất thường trong kịch bản trực tuyến là một trong những bài toán được quan tâm rộng rãi bởi khả năng ứng dụng cao trong các quá trình giám sát, phân tích dữ liệu thu thập được và báo cáo bất kỳ quan sát bất thường nào để đảm bảo môi trường hoạt động và vận hành an toàn. Đây là một chủ đề có tính ứng dụng cao do hầu hết dữ liệu hoạt động và vận hành đều đến từ các quá trình ngẫu nhiên theo thời gian (ví dụ như số lượt đọc/ghi dữ liệu hằng giờ của một máy trạm, phần trăm sử dụng tài nguyên số của một nhân viên ngân hàng hằng ngày, số lượt truy cập vào một trang web, hay các giao dịch tín dụng). Việc giám sát và phát hiện dữ liệu bất thường theo thời gian thực cho phép người điều hành kịp thời ngăn chặn và khắc phục các hành vi gian lận hay phá hoại.
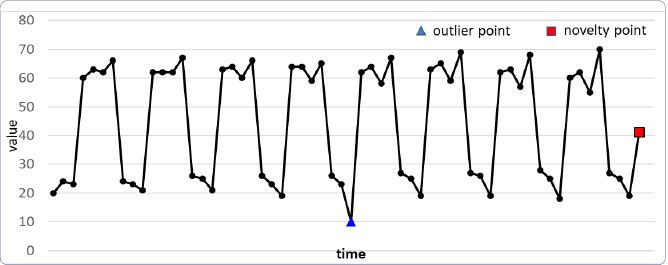
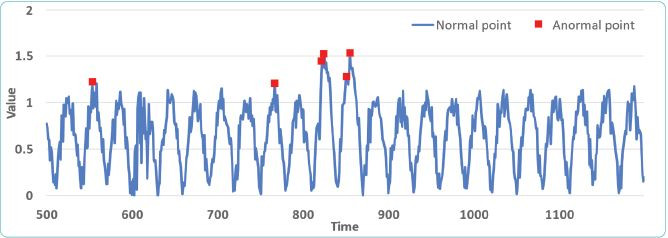
Hình 1: Ví dụ minh họa các điểm bất thường trong quá trình ngẫu nhiên theo thời gian
Bài toán phát hiện bất thường đề cập đến việc nhận dạng tự động các hiện tượng ngoại lệ được nhúng trong một lượng lớn dữ liệu bình thường (outlier detection) hoặc không lường trước được xuất hiện theo thời gian thực (novelty detection) (Hình 1). Trong các quá trình ngẫu nhiên theo thời gian, điểm ngoại lệ (outlier) thường được dùng để biểu diễn những quan sát bất thường chỉ kéo dài trong chốc lát, sau đó chuỗi thời gian trở lại bình thường. Điều này có nghĩa là chúng ta đã thu thập được các quan sát trong một khoảng thời gian trước và sau điểm ngoại lệ. Do đó, nó thường được áp dụng cho các bài toán phát hiện điểm bất thường dạng thức ngoại tuyến (offline detection). Trong bối cảnh dữ liệu đến theo thời gian thực (streaming data), có hai ràng buộc bổ sung đối với việc thiết kế mô hình phát hiện bất thường là:
- Mô hình chỉ có thể sử dụng dữ liệu lịch sử để thực hiện phát hiện.
- Việc phát hiện phải được thực hiện trong một khoảng thời gian nhất định (ngắn).
Nếu hai yêu cầu này được thỏa mãn, phương pháp này được gọi là phát hiện bất thường trực tuyến (Online detection).
Phát hiện bất thường là một chủ đề đầy thách thức, chủ yếu là do khó có đủ kiến thức và định nghĩa chính xác của “tính bất thường” trong một vấn đề cụ thể, điều này làm giảm hiệu quả của việc sử dụng những kỹ thuật học giám sát. Trong nhiều trường hợp, không có định nghĩa chung được đưa ra cho tính bất thường trước khi phát hiện. Đồng thời, dữ liệu bất thường được nhúng trong một lượng lớn dữ liệu bình thường là không đủ để xây dựng một lớp mới để có thể phân loại. Do đó, phương pháp phát hiện mới, lạ được định nghĩa tốt nhất như một phương pháp học không giám sát, tức là không có nhãn nào có sẵn và việc phát hiện chỉ có thể dựa trên các thuộc tính nội tại của dữ liệu.
Bất chấp thách thức của nó, trong những năm gần đây, phát hiện bất thường trở thành một chủ đề ngày càng thu hút nhiều sự quan tâm và nhiều kỹ thuật đã được nghiên cứu, đề xuất để giải quyết. Các kỹ thuật này đã được thực nghiệm chứng minh là có hiệu quả trong một số trường hợp, trong khi chúng có thể thất bại trong các trường hợp khác. Ví dụ, một số phương pháp được thiết kế dựa trên giả định đã có các mô hình chính xác của vấn đề đang xem xét, hoặc giả định đã biết các điều kiện bất thường. Những giả định này thường không hiệu quả trong thế giới thực. Trong một số nghiên cứu khác, phát hiện bất thường được hiểu đơn giản là phát hiện ngoại lệ. Tuy nhiên, sự đơn giản hóa này tạo ra các phương pháp không thể phát hiện ra các mẫu mới được hình thành bởi các quá trình ngẫu nhiên theo thời gian. Đặc biệt, phương pháp phát hiện tính mới được đề xuất dựa trên một kỹ thuật máy vector hỗ trợ (Support Vector Machine - SVM), trong đó, một số mẫu mới buộc phải được xác định trước trong tập dữ liệu đã có. Thay vì sử dụng thuật toán One-class SVM, các phương pháp phân loại bán giám sát cũng đã được phát triển trong đó mô hình được huấn luyện trên một số tập mẫu nhỏ đã được gán nhãn bình thường và bất thường, phương pháp phân loại không giám sát cũng được sử dụng cho phép tính điểm bất thường trong không gian được chiếu. Các tác giả Nguyen, H.T và Thái, NH (2019) đã đề xuất phương pháp phát hiện điểm bất thường trong cả kịch bản ngoại tuyến và trực tuyến, ứng dụng cho cả dữ liệu thời gian và không gian cho các cảm biến không dây. Phương pháp đề xuất được cải tiến từ phương pháp Hampel, dựa trên ngưỡng (rule-based), có thời gian thực thi thấp nên có khả năng ứng dụng cho các hệ thống giám sát trực tuyến. Mô hình có hạn chế là sử dụng giả định biết trước phân phối của dữ liệu và là dữ liệu độc lập và đồng nhất (IID). Tuy nhiên, nếu dữ liệu là không dừng (nonstationary), chẳng hạn như tồn tại các xu hướng hoặc tính thời vụ, thì phương pháp này có thể nhận được nhiều kết quả dương tính giả và/hoặc âm tính giả. Ví dụ, một điểm có thể được coi là bất thường nếu không tính đến yếu tố mùa vụ (season) nhưng được coi là một điểm bình thường nếu xem xét thêm yếu tố mùa vụ. Do đó, trong kịch bản trực tuyến, việc không có dữ liệu khiến việc xác định điểm bất thường trở nên phức tạp hơn rất nhiều và vẫn là chủ đề nghiên cứu có tính thời sự.
Trong bài viết này, chúng tôi xem xét một quá trình ngẫu nhiên thời gian rời rạc và đề xuất một thuật toán phi tham số cải tiến từ thuật toán ngưỡng nhằm làm giảm tỷ lệ dương tính giả (dữ liệu mới bị coi là điểm bất thường do nằm ngoài ngưỡng cho phép nhưng đã được phản ánh bởi một số ít dữ liệu trong quá khứ có tính mùa vụ) và giảm tỷ lệ âm tính giả (dữ liệu mới được coi là bình thường do nằm trong ngưỡng cho phép nhưng không được phản ánh bởi dữ liệu trong quá khứ). Thuật toán của chúng tôi được chia thành hai bước. Bước thứ nhất sử dụng thuật toán ngưỡng để tiền phân loại điểm dữ liệu mới. Bước thứ hai sử dụng thuật toán phân cụm để xác thực nhãn của điểm dữ liệu mới. Bước xác thực này làm giảm khả năng xảy ra ngụy biện sinh thái (Ecological fallacy). Do đó, làm giảm tỷ lệ dương tính giả và âm tính giả. Các thí nghiệm được thực hiện trên hai bộ dữ liệu bao gồm một bộ dữ liệu tự sinh và một bộ dữ liệu thực mô tả các giao dịch bằng thẻ tín dụng của người dùng ở châu Âu. Kết quả thực nghiệm chỉ ra rằng, thuật toán đề xuất giúp giảm thiểu đáng kể số lượng dương tính giả và âm tính giả so với thuật toán ngưỡng. Mô hình và thuật toán đề xuất có thể được ứng dụng rộng rãi trong các hệ thống giám sát thông tin giúp các ngân hàng, tổ chức tài chính kịp thời phát hiện các cuộc tấn công hoặc gian lận trong sử dụng dịch vụ.
II. Phát biểu bài toán
Cho một quá trình ngẫu nhiên thời gian rời rạc đại diện bởi χ(t) trong đó t=t0,t1,…,tN và xj là một trong những quan sát (các quan sát tuần tự theo thời gian rời rạc được gọi chung là điểm dữ liệu) của quá trình x tại thời điểm tj. Các quan sát này có thể là sự kiện, số lượt đọc/ghi dữ liệu, phần trăm sử dụng tài nguyên, ảnh, video, hoặc bất kỳ đối tượng nào được thu thập theo thời gian. Đặt Sn-1={x0,x1,…,xn-1} là một mẫu bao gồm toàn bộ quan sát thu thập được của quá trình x tính đến thời điểm tn-1. Tại thời điểm tn, hệ thống giám sát dữ liệu trực tuyến tiếp nhận quan sát mới xn. Hệ thống phân tích dữ liệu cần dựa trên mẫu Sn-1 đã thu thập được để phân loại xn là điểm bình thường hay bất thường với thời gian thực thi thấp.
III. Phương pháp đề xuất
Thuật toán ngưỡng (RB) sử dụng tham số ngưỡng để kiểm tra một điểm dữ liệu mới là bình thường (nếu nằm trong khoảng cho phép) hay bất thường. Ngưỡng thường được sử dụng là [μ-3σ, μ+3σ], trong đó dữ liệu được giả định tuân theo phân phối chuẩn, μ là giá trị trung bình, σ là phương sai. Ngưỡng này dựa trên quy tắc thực nghiệm được mô tả như sau:
Cho X là quan sát từ biến ngẫu nhiên có phân phối chuẩn, μ là giá trị trung bình của phân phối và σ là độ lệch chuẩn của nó, xác suất (P) để các giá trị của X nằm trong các khoảng tương ứng là:
P(μ - 1σ ≤ X ≤ μ + 1σ) ≈ 68,27%
P(μ - 2σ ≤ X ≤ μ + 2σ) ≈ 95,45%
P(μ - 3σ ≤ X ≤ μ + 3σ) ≈ 99,73%
Trong lý thuyết xác suất, bất đẳng thức Chebyshev tổng quát hơn, chứng minh rằng tối thiểu chỉ 75% giá trị phải nằm trong hai độ lệch chuẩn của giá trị trung bình và 88,89% trong ba độ lệch chuẩn đối với các phân phối xác suất khác nhau, tức là áp dụng cho các phân phối xác suất nói chung chứ không chỉ dành cho phân phối chuẩn. Cụ thể là:
P(|X - μ| ≥ m.σ) ≤ 1/m2
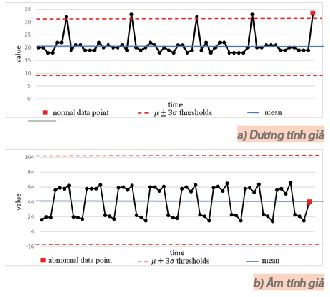
Tuy nhiên, một điểm dữ liệu mới có thể được phân loại là bình thường bởi thuật toán ngưỡng (thuộc khoảng [μ-3σ, μ+3σ]) nhưng nó thực sự có phân bố khác với các điểm dữ liệu trong lịch sử (âm tính giả), hoặc nó được phân loại là bất thường nhưng đã từng xảy ra có tính chu kỳ (dương tính giả). Ví dụ minh họa cho các trường hợp này được thể hiện trong Hình 2.
Hình 2: Minh họa một số trường hợp thất bại của thuật toán ngưỡng
Trong bài viết này, chúng tôi đề xuất một thuật toán cải tiến từ thuật toán ngưỡng mới (đặt tên là CRB) bằng cách sử dụng bất đẳng thức Chebyshev để làm ngưỡng tiền phân loại và kết hợp thuật toán phân cụm để xác thực nhãn của điểm dữ liệu. Với mục tiêu làm giảm tỷ lệ dương tính giả và âm tính giả, thuật toán phân cụm được sử dụng để phân chia dữ liệu thành các cụm có tính đại diện và xem xét tính gắn kết giữa các quan sát trong cụm. Thuật toán k-means được sử dụng để phân cụm dữ liệu trong đó k ≥ m để đảm bảo bán kính lớn nhất của các cụm không vượt quá một phương sai σ. Một cụm có tính đại diện là cụm có số lượng quan sát tối thiểu để được coi là có sự tồn tại của yếu tố mùa vụ. Số lượng quan sát tối thiểu thường được xác định theo kinh nghiệm, một giá trị trong khoảng [3, 5] thường được sử dụng trong hầu hết các vấn đề. Mức độ gắn kết (d) của các quan sát trong cụm ci có tâm là oi được đo bởi trung bình của bình phương khoảng cách từ các quan sát tới tâm cụm:
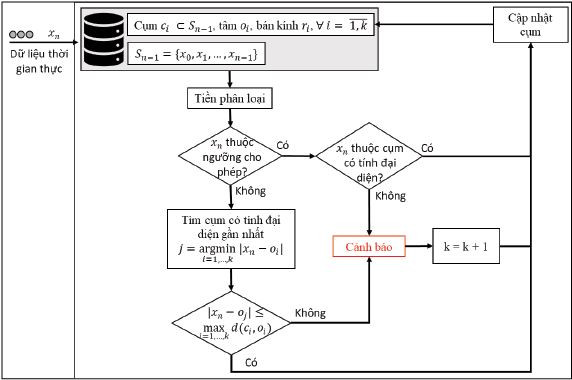
Với sz(ci) là số lượng quan sát được phân vào cụm ci, ∀i= (1,k). Độ đo này có lợi thế về mặt thời gian tính toán do tử số đã được tính trong quá trình phân cụm bởi thuật toán k-means. Quá trình thực thi của thuật toán đề xuất được mô tả trực quan trong Hình 3.
Hình 3: Thuật toán CRB phát hiện điểm dữ liệu bất thường trong kịch bản trực tuyến
Ở bước tiền phân loại, thuật toán RB được sử dụng để xác định phân loại của điểm dữ liệu mới. Ngưỡng được tính dựa trên tất cả các điểm dữ liệu lịch sử đã thu thập được (suy luận quần thể). Nếu điểm dữ liệu mới nằm trong ngưỡng cho phép, nhãn của điểm dữ liệu này được xác thực là bình thường nếu nó thuộc một cụm có tính đại diện. Bước xác nhận này làm giảm khả năng xảy ra âm tính giả. Nếu điểm dữ liệu mới nằm ngoài ngưỡng cho phép, nó chỉ thực sự là điểm bất thường khi thêm nó vào cụm gần nhất sẽ làm giảm mức độ gắn kết tối thiểu của các cụm đã có. Bước xác nhận này làm giảm khả năng xảy ra dương tính giả. Việc kết hợp thuật toán ngưỡng (đóng vai trò suy luận dựa trên quần thể) và thuật toán phân cụm (suy luận dựa trên cụm cá thể) giúp làm giảm nguy cơ xảy ra ngụy biện sinh thái.
IV. Thực nghiệm
1. Dữ liệu
Trong bài viết này, chúng tôi sử dụng 02 bộ dữ liệu để thử nghiệm được mô tả như sau:
- Tập dữ liệu tự sinh (SD): Tái hiện từ Ma, Junshui và Perkins (2003) được tính theo công thức:
Trong đó, N=1200, n(t) là một nhiễu Gau với μ = 0, σ = 0,1
Với n1(t) là tuân theo phân phối chuẩn N(0, 0.5)
- Tập dữ liệu thực (RD): Chứa các giao dịch thực tế thực hiện bằng thẻ tín dụng của chủ thẻ châu Âu, thu thập bởi nhóm nghiên cứu Đại học Libre, Brussels, Bỉ (2015), trong đó có 492 gian lận được phát hiện trong tổng số 284.807 giao dịch. Các giao dịch đã được sắp xếp theo thứ tự thời gian giao dịch. Trong mô phỏng phát hiện giao dịch gian lận kịch bản trực tuyến, chúng tôi chỉ thực hiện trên 2.000 giao dịch đầu tiên để dễ dàng trình bày kết quả thí nghiệm.
2. Đánh giá hiệu quả của phương pháp đề xuất
Chúng tôi thực hiện mô phỏng thuật toán phát hiện điểm bất thường trong kịch bản trực tuyến với 500 điểm dữ liệu đầu tiên được coi là dữ liệu lịch sử (dùng để xác định các thuộc tính của phân phối dữ liệu). Với mỗi điểm dữ liệu tiếp theo, chúng tôi sử dụng thuật toán đề xuất CRB để xác định phân loại là bình thường hay bất thường. Kết quả được so sánh với thuật toán RB thông qua các chỉ số:
- FN (âm tính giả): Số điểm có nhãn là bất thường nhưng được phân loại là bình thường.
- TN (âm tính thật): Số điểm có nhãn là bình thường và được phân loại là bình thường.
- FP (dương tính giả): Số điểm có nhãn là bình thường nhưng được phân loại là bất thường.
- TP (dương tính thật): Số điểm có nhãn là bất thường và được phân loại là bất thường.
Hình 4: Kết quả phát hiện điểm bất thường cho tập dữ liệu SD
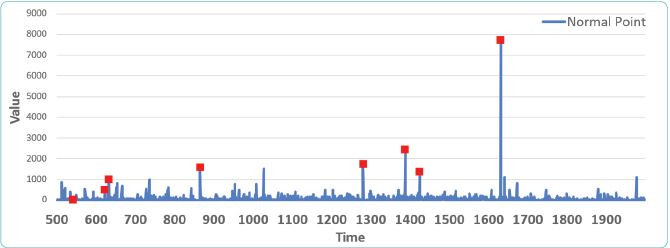
Hình 5: Kết quả phát hiện điểm bất thường cho tập dữ liệu RD
Hình 4 và 5 trực quan hóa các điểm dữ liệu theo thời gian. Trong Hình 4, một số điểm dữ liệu có giá trị cao bất thường đều đã được đánh dấu là điểm bất thường. Điểm bất thường đầu tiên mặc dù có giá trị không quá cao so với các điểm trước đó nhưng nó làm xuất hiện cụm mới chưa từng được phản ánh trong dữ liệu lịch sử. Do đó, nó cũng được coi là bất thường. Điều này xảy ra tương tự trong Hình 5. Hơn nữa, điểm bất thường đầu tiên trong Hình 5 có giá trị thấp hơn so với các điểm dữ liệu trước đó và cũng tạo cụm mới nên được xem như một điểm bất thường.
Bảng 1: Chỉ số đánh giá hiệu quả thuật toán
So với thuật toán ngưỡng RB, thuật toán CRB thể hiện sự hiệu quả thông qua chỉ số FN, FP và F1score. Dựa vào Bảng 1 ta thấy, thuật toán CRB thu được FN và FP đều thấp hơn hoặc bằng so với thuật toán RB. Tức là, thuật toán CRB giúp làm giảm tỷ lệ âm tính giả và dương tính giả so với thuật toán RB. Hơn nữa, do tính chất hiếm của các điểm bất thường nên chúng tôi sử dụng thêm chỉ số F1score để đánh giá hiệu quả giữa các thuật toán. Bảng 1 cũng chỉ ra thuật toán CRB có chỉ số F1score cao hơn trên cả hai bộ dữ liệu. Chúng tôi lưu ý rằng chỉ số F1score không phản ánh độ chính xác của phân loại so với nhãn sẵn có trong dữ liệu do định nghĩa điểm bất thường là khác nhau. Do đó, nhìn chung, thuật toán đề xuất của chúng tôi đem lại kết quả tốt hơn so với thuật toán ngưỡng khi có cùng định nghĩa điểm bất thường trên hai bộ dữ liệu này.
V. Kết luận
Để góp phần phát triển các kỹ thuật giám sát và đảm bảo an toàn thông tin trong lĩnh vực tài chính, ngân hàng, chúng tôi đã xem xét bài toán phát hiện điểm dữ liệu bất thường trực tuyến để kịp thời phát hiện thông tin đến từ các hoạt động phá hoại, gian lận và đưa ra cảnh báo. Chúng tôi đã đề xuất một thuật toán phát hiện bất thường dựa trên dữ liệu, được cải tiến từ thuật toán ngưỡng nhằm làm giảm tỷ lệ phân loại sai. Kết quả thực nghiệm trên cả bộ dữ liệu thực và tự sinh đã chỉ ra tính hiệu quả và khả năng ứng dụng thuật toán cho các bài toán thực tế. Đặc biệt, mô hình và thuật toán đề xuất có thể áp dụng rộng rãi cho các bài toán phát hiện bất thường trong lĩnh vực tài chính, ngân hàng có khối lượng giao dịch và thông tin cần xử lý hằng ngày là rất lớn, đòi hỏi tính chính xác cao và trả kết quả nhanh chóng. Với mục tiêu nâng cao an toàn hệ thống, các tổ chức tài chính, ngân hàng có thể áp dụng mô hình và thuật toán đề xuất để phát triển hệ thống giám sát và cảnh báo khi có các giao dịch hoặc hoạt động trên cơ sở dữ liệu bất thường.
Tài liệu tham khảo:
1. Dasgupta, Dipanker, and Stephanie, Forrest, Novelty Detection in Time Series Data Using Ideas from Immunology, In Proceedings of the 5th International Conference on Intelligent Systems, Reno, Nevada, June 19-21, 1996.
2. Ypma, Alexander, and Rober P. Duin, Novelty Detection Using Self-Organizing Maps, in Progress in Connectionist Based Information Systems, pp 1322-1325, London: Springer, 1997.
3. Keogh, E., S Lonardi, and W Chiu, Finding Surprising Patterns in a Time Series Database In Linear Time and Space, In the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp 550-556, Edmonton, Alberta, Canada, July 23 - 26, 2002.
4. Marco A.F. Pimentel, David A. Clifton, Lei Clifton, Lionel Tarassenko, A review of novelty detection, Signal Processing 99, 215-249, 2014.
5. Ma, Junshui, and Simon Perkins, Online novelty detection on temporal sequences, Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2003.
6. Kozma, R., M. Kitamura, M. Sakuma, and Y. Yokoyama, Anomaly Detection by Neural Network Models and Statistical Time Series Analysis, in Proceedings of IEEE International Conference on Neural Networks, Orlando, Florida, June 27-29, 1994.
7. Fabrizio Angiulli, Fabio Fassetti, and Luigi Palopoli, Detecting outlying properties of exceptional objects. ACM Transactions on Database Systems 34, 1, 1-62, 2009.
8. Samet Akcay, Amir Atapour-Abarghouei, and Toby P Breckon, GANomaly: Semi-supervised anomaly detection via adversarial training, In ACCV. Springer, 622 - 637, 2018.
9. Fabrizio Angiulli, Fabio Fassetti, Giuseppe Manco, and Luigi Palopoli, Outlying property detection with numerical attributes. Data Mining and Knowledge Discovery 31, 1, 134 - 163, 2017.
10. Guilherme O Campos, Arthur Zimek, Jorg Sander, Ricardo JGB Campello, Barbora Micenková, Erich Schubert, Ira Assent, and Michael E Houle, On the evaluation of unsupervised outlier detection: Measures, datasets, and an empirical study, Data Mining and Knowledge Discovery 30, 4 (2016), 891 - 927, 2017.
11. Azzedine Boukerche, Lining Zheng, and Omar Alfandi, Outlier Detection: Methods, Models and Classifications, Comput. Surveys, 2020.
12. Campbell, Colin, Kristin P. Bennett, A Linear Programming Approach to Novelty Detection, in Advances in Neural Information Processing Systems, vol 14, 2001.
13. Dan Xu, Elisa Ricci, Yan Yan, Jingkuan Song, and Nicu Sebe, Learning Deep Representations of Appearance and Motion for Anomalous Event Detection. In BMVC, 2015
14. Lukas Ruff, Robert A Vandermeulen, Nico Gornitz, Alexander Binder, Emmanuel Moller, Klaus-Robert Moller, and Marius Kloft, Deep semi-supervised anomaly detection, ICLR, 2020.
15. Radu Tudor Ionescu, Fahad Shahbaz Khan, Mariana-Iuliana Georgescu, and Ling Shao, Object-centric auto-encoders and dummy anomalies for abnormal event detection in video, In CVPR. 7842 - 7851, 2020.
16. Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel, Deep Learning for Anomaly Detection: A Review, ACM Comput. Surv. 54, 2, Article 38, 38 pages, 2022.
17. Nguyen, H.T. and Thai, N.H, Temporal and spatial outlier detection in wireless sensor networks. ETRI Journal, 41: 437-451, 2019.
18. Spinosa, Eduardo and de Carvalho, Andre and Gama, João., Novelty detection with application to data streams, Intell. Data Anal. 13. 405-422, 2009.
19. Ma, Junshui & Perkins, Simon, Online novelty detection on temporal sequences. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 613-618, 2003.
20. Dal Pozzolo, Andrea & Caelen, Olivier & Johnson, Reid & Bontempi, Gianluca, Calibrating Probability with Undersampling for Unbalanced Classification, IEEE Symposium Series on Computational Intelligence, 2015.
ThS. Nguyễn Văn Sơn, ThS. Nguyễn Văn Tân Học viện Kỹ thuật Mật mã
Bài viết đưa ra phương pháp bảo mật đa lớp để đảm bảo truyền nhận thông tin từ thiết bị IoT đến máy chủ qua mạng di động. Phương pháp đề xuất này sử dụng nhiều yếu tố khóa lồng nhau, khi được triển khai thực tế chúng sẽ cung cấp một giải pháp tổng thể về kết nối an toàn cao.
Bình luận của bạn đã được gửi và sẽ hiển thị sau khi được duyệt bởi ban biên tập.
Ban biên tập giữ quyền biên tập nội dung bình luận để phù hợp với qui định nội dung của Báo.
Nghị quyết 10-NQ/TW về phát triển kinh tế có vốn đầu tư nước ngoài phản ánh sự phát triển mới trong tư duy hoạch định chính sách của Việt Nam trước những biến động sâu sắc của kinh tế thế giới, từ mục tiêu bổ sung nguồn lực đầu tư, FDI được nhìn nhận như một cấu phần của chiến lược nâng cấp vị thế quốc gia trong chuỗi giá trị toàn cầu.
8 giờ 30 phút hôm nay (17/10) tại trụ sở Bộ Biên tập Báo Nhân Dân, 71 Hàng Trống, Hà Nội, Báo Nhân Dân phối hợp cùng Viện Chiến lược phát triển kinh tế số (IDS) tổ chức tường thuật trực tiếp tọa đàm “Thực thi Chiến lược tài chính toàn diện quốc gia: Cơ hội để hộ kinh doanh tiếp cận công nghệ tài chính, thúc đẩy tăng trưởng”.
Việt Nam có nguồn nhân tài công nghệ nổi bật trong khu vực, nhưng các nhà sáng lập đôi khi quá tập trung vào những gì AI có thể làm mà bỏ qua nhu cầu thực tế của người dùng...
Nghiên cứu này là một chuyên đề của Series nghiên cứu về tác động của chính sách thuế quan mới của Mỹ tới nền kinh tế Việt Nam, được thực hiện bởi Viện NCKH Ngân hàng, Học viện Ngân hàng trong tháng 4/2025.
Để thực hiện tốt Chiến lược, đảm bảo mục tiêu “không bỏ ai lại phía sau”, cần tạo mọi điều kiện giúp các đối tượng yếu thế có khả năng tiếp cận với các kênh “tín dụng trắng”. Đó là các kênh cung ứng dịch vụ tài chính chính thức, bền vững, hoạt động trong khuôn khổ của luật pháp và dưới sự quản lý của các cơ quan nhà nước có thẩm quyền.
Hơn 5 triệu hộ kinh doanh cá thể phân bố chủ yếu tại các khu vực đô thị lớn như Hà Nội, TP.HCM và Đà Nẵng, tạo việc làm cho gần 8,5 triệu lao động và trở thành một phần không thể thiếu trong nền kinh tế. Sự hiện diện rộng khắp này cho thấy tầm quan trọng của các tiểu thương trong việc thúc đẩy kinh tế địa phương cũng như quốc gia.
6 tháng đầu năm 2026, kinh tế thế giới liên tục đối mặt với những biến động khó lường. Xung đột địa chính trị leo thang, giá dầu và giá vàng biến động mạnh, xu hướng bảo hộ thương mại gia tăng, trong khi chính sách tiền tệ của các nền kinh tế lớn liên tục thay đổi đã tạo ra những “cơn sóng” mới đối với các nền kinh tế có độ mở cao như Việt Nam.
Muốn đạt tăng trưởng hai con số, Việt Nam cần chuyển trọng tâm sang cải cách vi mô, tháo gỡ điểm nghẽn cho doanh nghiệp, khơi thông nguồn lực và thúc đẩy đổi mới sáng tạo.
Việc Chính phủ thống nhất đổi tên dự án “Luật Đô thị đặc biệt” thành “Luật Phát triển đô thị” thoạt nhìn có thể được xem là một sự điều chỉnh về tên gọi.
Để hỗ trợ mục tiêu tăng trưởng GDP 10% trong năm 2026, chỉ trong hai tháng 5 và 6, cơ quan quản lý đã liên tiếp ban hành nhiều chính sách nhằm tăng thanh khoản, mở rộng dư địa tín dụng và ưu tiên vốn cho các dự án trọng điểm. Tuy nhiên, theo chuyên gia, để tránh hệ lụy trong tương lai, các chính sách này cần có thời hạn rõ ràng và lộ trình rút dần khi điều kiện thị trường ổn định hơn.
GDP quý II/2026 tăng 8,39% so với cùng kỳ, 6 tháng đầu năm tăng 8,18%. Mức tăng ấn tượng nhất kể từ trước đến nay này đến từ khu vực nào và sự khác biệt của tăng trưởng kinh tế năm nay so với 10 năm trở lại đây là gì? Bà Nguyễn Thị Mai Hạnh, Trưởng ban Ban Hệ thống tài khoản quốc gia, Cục Thống kê (Bộ Tài chính) trao đổi về vấn đề này.
Trong bối cảnh kinh tế châu Á chậm lại do bất ổn toàn cầu, Việt Nam nổi lên như một điểm sáng vĩ mô với tăng trưởng GDP 6 tháng đạt 8,18%. Dòng vốn FDI và khối sản xuất công nghệ đang trở thành bệ đỡ vững chắc nâng đỡ triển vọng năm 2026.
Mới đây, UBND TP. Hồ Chí Minh đã ban hành kế hoạch tổ chức công bố phiên bản thử nghiệm Hạ tầng xúc tiến đầu tư trên môi trường số TP. Hồ Chí Minh (HCMCInvest), đánh dấu bước triển khai mới trong chương trình chuyển đổi số đối với hoạt động xúc tiến đầu tư của Thành phố. Nền tảng này đồng thời thể hiện định hướng đổi mới phương thức xúc tiến đầu tư của TP. Hồ Chí Minh theo hướng hiện đại, minh bạch, tăng cường ứng dụng công nghệ số và trí tuệ nhân tạo nhằm nâng cao hiệu quả hỗ trợ nhà đầu tư trong quá trình tìm hiểu cơ hội và tiếp cận thông tin.
Ngày 10/7, tại Hà Nội, Bộ Khoa học và Công nghệ tổ chức Hội thảo lấy ý kiến về triển khai nhiệm vụ hỗ trợ lãi suất vay của Quỹ Đổi mới công nghệ quốc gia (NATIF). Theo phương án được đưa ra, doanh nghiệp đầu tư ứng dụng, chuyển giao, đổi mới công nghệ và đổi mới sáng tạo có thể được hỗ trợ 50% lãi suất vay theo hợp đồng tín dụng, nhưng không vượt quá 6%/năm trong thời gian tối đa 5 năm. Chính sách dự kiến được triển khai thí điểm đối với 20 doanh nghiệp trước khi tổng kết, hoàn thiện và nhân rộng.
Quy hoạch Thủ đô Hà Nội với tầm nhìn thế kỷ đang kích hoạt một cuộc đại dịch chuyển của dòng vốn bất động sản ra khỏi khu vực lõi lịch sử. Khi mô hình đô thị đa cực hình thành cùng sự phát triển mạnh mẽ của hạ tầng kết nối, quy luật định giá của thị trường sẽ được viết lại.
Biên bản cuộc họp chính sách tháng 6 của Fed cho thấy, mặc dù lạm phát đang là mối quan tâm hàng đầu, song các nhà hoạch định chính sách lại bất đồng về triển vọng lạm phát. Điều đó cho thấy lộ trình lãi suất trong thời gian tới của Fed vẫn chưa rõ ràng.
Nghị quyết số 57-NQ/TW của Bộ Chính trị về đột phá phát triển khoa học, công nghệ, đổi mới sáng tạo và chuyển đổi số quốc gia đã đặt nền móng cho mô hình tăng trưởng mới dựa trên tri thức và đổi mới sáng tạo. Sau giai đoạn xây dựng nền tảng, yêu cầu đặt ra là tạo ra nhiều sản phẩm, doanh nghiệp và giá trị mới cho nền kinh tế.
Muốn xây dựng thành công Trung tâm Tài chính Quốc tế tại Việt Nam (VIFC), điều quan trọng không chỉ những ưu đãi vượt trội mà là một hành lang pháp lý minh bạch, đơn giản và đáng tin cậy. Đây là thông điệp được các chuyên gia quốc tế chia sẻ tại Diễn đàn Tài chính Việt Nam 2026 diễn ra ở Đà Nẵng ngày 9/7.
Bất chấp căng thẳng giữa Mỹ và Iran leo thang đã đẩy giá dầu tăng cao, bất chấp việc Biên bản cuộc họp tháng 6 cho thấy Fed ‘diều hâu’ hơn, song đồng USD vẫn tiếp tục suy yếu và đang hướng tới ngày giảm giá thứ ba liên tiếp trong ngày cuối tuần (thứ Sáu 10/7). Điều gì đang diễn ra đối với đồng bạc xanh?
Thị trường vàng thế giới trong nửa đầu năm 2026 đã chứng kiến một hành trình đầy kịch tính, đi từ sự thăng hoa với những kỷ lục vô tiền khoáng hậu đến đợt điều chỉnh giảm sâu nhất trong hơn một thập kỷ qua.
Việt Nam đang trở nên dễ tiếp cận hơn đối với các quỹ hưu trí và nhà đầu tư tổ chức Úc, nhưng để chuyển sự quan tâm thành dòng vốn thực tế, thị trường cần tiếp tục củng cố tính ổn định của chính sách, chiều sâu tài chính và nguồn tài sản đủ chuẩn đầu tư.
Trao đổi với phóng viên Báo Tài chính - Đầu tư, Thứ trưởng Bộ Tài chính Trần Quốc Phương cho biết, câu chuyện của kinh tế Việt Nam 6 tháng đầu năm không chỉ đơn thuần nằm ở con số tăng trưởng 8,18%, mà còn ở sự chuyển dịch tích cực của các các động lực tăng trưởng. Đây là nền tảng cho việc thực hiện mục tiêu tăng trưởng 2 con số của cả năm 2026.
Việc Việt Nam bắt đầu triển khai thí điểm thị trường giao dịch tài sản mã hóa không chỉ mở ra một lĩnh vực tài chính mới mà còn đặt nền móng cho một kênh huy động vốn khác biệt bên cạnh tín dụng ngân hàng và thị trường chứng khoán. Nếu được vận hành hiệu quả trong khuôn khổ pháp lý chặt chẽ, cơ chế mã hóa tài sản thực có thể tạo thêm cơ hội tiếp cận nguồn lực tài chính cho doanh nghiệp, đặc biệt là khu vực doanh nghiệp nhỏ và vừa.
Từ các dự án hạ tầng quốc gia đến những công trình liên kết vùng, nhu cầu vốn quy mô lớn đang mở ra cơ hội phát triển cho hoạt động cho vay hợp vốn. Cùng với các cơ chế điều hành mới của NHNN, các hoạt động tài trợ dự án được kỳ vọng sẽ sôi động hơn.
Lãnh đạo đang đối mặt với áp lực ngày càng tăng để hỗ trợ việc áp dụng trí tuệ nhân tạo trong toàn doanh nghiệp một cách nhanh chóng. Nhưng với rủi ro nào? Lãnh đạo CNTT làm sáng tỏ cách họ cân bằng giữa giám sát và đổi mới.

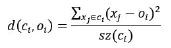
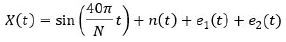
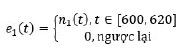
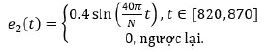
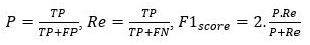








![[Emagazine] Giữ vững ổn định vĩ mô, mở dư địa cho tăng trưởng hai con số](https://vkts.1cdn.vn/thumbs/540x360/2026/07/14/thoibaonganhang.vn-stores-news_dataimages-2026-072026-02-17-_chatgpt-image-16-59-47-2-thg-7-202620260702170006.png "[Emagazine] Giữ vững ổn định vĩ mô, mở dư địa cho tăng trưởng hai con số")














![[Gặp gỡ thứ Tư] 'Việt Nam đang xây nền móng cho dòng vốn dài hạn'](https://vkts.1cdn.vn/thumbs/540x360/2026/07/08/t.ex-cdn.com-nhadautu.vn-560w-files-news-2026-07-06-_dscf5488-2-0837.jpg "[Gặp gỡ thứ Tư] 'Việt Nam đang xây nền móng cho dòng vốn dài hạn'")



