
Nguồn dữ liệu mới phục vụ điều hành chính sách tiền tệ: Kinh nghiệm quốc tế và hàm ý cho Việt Nam
Nghiên cứu - Trao đổi - Ngày đăng : 11:09, 29/06/2023
Bài viết đề xuất một số hàm ý cho Việt Nam trong việc phát triển và quản lí các nguồn dữ liệu mới nhằm đáp ứng có hiệu quả công tác điều hành CSTT của Ngân hàng Nhà nước Việt Nam (NHNN).
Tóm tắt: Điều hành chính sách tiền tệ (CSTT) là chức năng quan trọng hàng đầu của ngân hàng trung ương (NHTW) tại mỗi quốc gia. Trong trường hợp công cụ điều hành thông thường không còn hữu dụng, NHTW có thể áp dụng các công cụ CSTT phi truyền thống để ứng phó với tình trạng kinh tế bất thường. Để các công cụ phi truyền thống đạt hiệu quả tối đa, việc phát triển và khai thác nguồn dữ liệu mới tại NHTW là hết sức cần thiết. Bài viết tập trung phân tích, đánh giá thực tiễn phát triển và ứng dụng dữ liệu mới trong điều hành CSTT tại một số quốc gia điển hình, bao gồm Hoa Kỳ, Trung Quốc, Ý và Nhật Bản. Cụ thể, kinh nghiệm của từng quốc gia sẽ được phân tích theo ba “lát cắt” chính: (i) Tổng quan các loại dữ liệu mới; (ii) Lợi ích của dữ liệu mới đối với điều hành CSTT và kinh tế vĩ mô; (iii) Quản trị dữ liệu mới. Trên cơ sở đó, bài viết đề xuất một số hàm ý cho Việt Nam trong việc phát triển và quản lí các nguồn dữ liệu mới nhằm đáp ứng có hiệu quả công tác điều hành CSTT của Ngân hàng Nhà nước Việt Nam (NHNN).
Từ khóa: Nguồn dữ liệu mới; NHTW; điều hành CSTT; kinh nghiệm quốc tế.
NEW DATA SOURCES FOR MONETARY POLICY MANAGEMENT:
INTERNATIONAL EXPERIENCE AND IMPLICATIONS FOR VIETNAM
INTERNATIONAL EXPERIENCE AND IMPLICATIONS FOR VIETNAM
Abstract: Monetary policy management is the core function of the central bank in every nation. If conventional tools appear ineffective, the central bank could adopt unconventional monetary policy measures to cope with the extraordinary economic situation. For the central bank to operate unconventional monetary policy with optimum efficacy, it is imperative that new data sources be developed and utilized. This paper analyzes and evaluates the curent situation of creating and applying new data sources in supporting the monetary policy management of four typical economies: the U.S., China, Italy and Japan. The analysis of each country’s experience focuses on three main aspects: (i) Overview of new data sources; (ii) Benefits of new data for monetary and macroeconomic policy management; (iii) New data management. On this premise, the paper suggests specific implications for developing and maintaining new data sources to effectively support the State Bank of Vietnam’s monetary policy management.
Keywords: New data sources; central bank; monetary policy management; international experience.
1. Giới thiệu
Sự phát triển nhanh chóng của khoa học công nghệ trong thời gian qua đã tạo ra sự bùng nổ về thông tin, dẫn đến kỉ nguyên mới của dữ liệu. Theo ước tính của World Bank, tính đến cuối năm 2022, đã có 5,2 tỉ người sử dụng Internet và hơn 8,6 tỉ người sử dụng điện thoại di động để liên lạc và giao dịch, điều này tạo ra một trữ lượng dữ liệu và thông tin lớn chưa từng thấy trên phạm vi toàn cầu. Nhiều đổi mới đã được thực hiện theo hướng nâng cao năng lực công nghệ để tạo lập, lưu trữ, phân tích dữ liệu từ nhiều nguồn và cho nhiều mục tiêu khác nhau. Khoảng 2,5 triệu byte dữ liệu được tạo ra mỗi ngày và khoảng 90% dữ liệu hiện có được tạo ra chỉ trong hai năm qua (Tomar và cộng sự, 2016). Thực tế, có một khối lượng dữ liệu khổng lồ mà các khu vực tư nhân và khu vực công đang lưu trữ. Lượng dữ liệu lớn đáng kinh ngạc này có thể giúp các nhà hoạch định chính sách hiểu thêm về nền kinh tế vĩ mô và kinh tế vi mô. Sau cuộc khủng hoảng tài chính toàn cầu 2007 - 2009, việc thu thập dữ liệu trong lĩnh vực tài chính - ngân hàng ngày càng được chú trọng và phát triển hơn đối với cơ quan quản lí và các nhà đầu tư. Bên cạnh đó, NHTW các nước ngày càng chú trọng đến việc phân tích, sử dụng nguồn dữ liệu mới trong công tác điều hành (Nymand - Andersen và Pantelidis, 2018). NHTW có thể sử dụng nguồn dữ liệu trong nhiều lĩnh vực như là điều hành CSTT, ổn định tài chính, nghiên cứu và thống kê (Cornelli và cộng sự, 2022).
Tuy nhiên, cuộc khủng hoảng tài chính toàn cầu cho thấy, số liệu thống kê truyền thống khó có thể phản ánh vấn đề một cách toàn diện, do đó, làm hạn chế khả năng đối phó kịp thời của các cơ quan chức năng. Việc đưa ra các kết luận dựa trên nguồn thông tin không đầy đủ, thiếu chính xác tiềm ẩn rất nhiều rủi ro. Thực tế những năm gần đây cũng cho thấy, nếu chỉ trông chờ vào dữ liệu vĩ mô tổng thể thì chưa thể có đủ thông tin cần thiết cho công tác hoạch định chính sách nói chung. Thay vào đó, các nhà tạo lập chính sách cần phải mở rộng hơn tới các cấp dữ liệu chi tiết, có tính chuyên sâu cao nhằm hỗ trợ đắc lực hơn nữa các quyết sách của NHTW. Điều này đã và đang tạo lập một xu thế phát triển mới về thống kê vi mô. Dựa trên dữ liệu vi mô, NHTW có thể nắm bắt chặt chẽ xu hướng, diễn biến trên thị trường tiền tệ, giúp các cán bộ chuyên trách nắm được cơ chế truyền tải của CSTT cũng như cho phép nắm bắt được các dữ liệu tổng thể và nâng cao chất lượng dự báo. Tại các nước phát triển, ngoài việc đưa ra mục tiêu cơ bản của CSTT như lạm phát, thất nghiệp… việc tập hợp các dữ liệu vi mô gắn với cơ chế truyền tải và tác động của các biện pháp điều hành CSTT đối với thu nhập và phúc lợi cũng đã thúc đẩy khá tốt hiệu quả của CSTT.
Tại Việt Nam, dữ liệu thống kê phục vụ cho việc điều hành CSTT của NHNN chủ yếu được lấy từ nguồn báo cáo thống kê do các đơn vị thuộc NHNN và các tổ chức tín dụng, chi nhánh ngân hàng nước ngoài thực hiện, theo quy định tại Thông tư số 11/2018/TT-NHNN sửa đổi, bổ sung một số điều của Thông tư số 35/2015/TT-NHNN ngày 31/12/2015 của Thống đốc NHNN quy định chế độ báo cáo thống kê. Bên cạnh số liệu báo cáo từ các tổ chức tín dụng, NHNN đã tích hợp với các cơ sở dữ liệu chuyên sâu khác như chương trình quản lí kho quỹ, hệ thống ngân hàng lõi, trung tâm thông tin tín dụng, hệ thống thanh toán... trở thành cơ sở dữ liệu tổng hợp, toàn diện về kinh tế, tài chính, tiền tệ và hoạt động ngân hàng, đáp ứng nhu cầu thông tin, dữ liệu trong ngành Ngân hàng, bao gồm: Dữ liệu thống kê kinh tế vĩ mô (thương mại, đầu tư, giao dịch vốn và tài chính, ngân sách…), dữ liệu thống kê tiền tệ - ngân hàng (Tô Huy Vũ, 2016). Trong thời gian vừa qua, nhằm đáp ứng yêu cầu thông tin ngày càng cao trước bối cảnh thị trường tài chính tiền tệ có sự chuyển biến mạnh mẽ trong giai đoạn Cách mạng công nghiệp lần thứ tư (CMCN 4.0) và toàn cầu hóa, NHNN đã liên tục chỉnh sửa, bổ sung các quy định về chế độ báo cáo1. Điều này giúp đáp ứng phần nào nhu cầu thông tin của các đơn vị trực thuộc NHNN. Dù vậy, việc các nền tảng công nghệ mới ra đời như Blockchain, Internet vạn vật… đã mở ra cơ hội cho việc bổ sung, cập nhật thông tin, dữ liệu mới giúp phục vụ tốt hơn công tác điều hành CSTT của NHNN.
Để thích ứng linh hoạt trong bối cảnh hội nhập kinh tế, tài chính quốc tế ngày càng sâu rộng, đối phó với vấn đề bất ổn tài chính, thích nghi với sự thay đổi môi trường tài chính - tiền tệ, NHNN cũng đã nhận thức rằng, dữ liệu truyền thống là không đủ và các nhà hoạch định CSTT cần dữ liệu chi tiết hơn. Rõ ràng, dữ liệu chi tiết nếu được thiết lập đúng cách, có thể đáp ứng được nhiều hơn các mục tiêu của hoạch định CSTT thông qua việc: (i) Giúp nâng cao hiểu biết về cơ chế truyền tải CSTT; (ii) Cho phép hiểu rõ hơn về dữ liệu tổng hợp, từ đó hỗ trợ hiệu quả cho công tác phân tích và dự báo; (iii) Tăng cường tính linh hoạt của dữ liệu tổng hợp, do chúng có thể được điều chỉnh để thích nghi với sự đổi mới CSTT, tài chính trong mỗi thời kì.
Những vấn đề trên đòi hỏi NHNN cần nghiên cứu, tìm hiểu và khai thác các nguồn dữ liệu mới trong công tác hoạch định CSTT. Điều này góp phần đảm bảo các quyết sách của NHNN trong lĩnh vực tiền tệ đúng và trúng mục tiêu, bám sát diễn biến của thị trường, bắt kịp xu hướng điều hành CSTT của thế giới. Bài viết này hướng tới giải quyết 03 mục tiêu chính như sau: (1) Tổng quan lí thuyết về nguồn dữ liệu cho điều hành CSTT; (2) Phân tích kinh nghiệm quốc tế về xây dựng và ứng dụng dữ liệu mới trong điều hành CSTT; (3) Đề xuất hàm ý cho Việt Nam đối với việc sử dụng dữ liệu mới phục vụ điều hành CSTT.
2. Tổng quan về nguồn dữ liệu cho điều hành CSTT
Trong bài viết này, nguồn dữ liệu cho điều hành CSTT được định nghĩa là các dữ liệu hữu ích, dùng để phân tích thông tin nhằm hỗ trợ công tác điều hành CSTT và ổn định hệ thống tài chính. Quá trình khảo lược về nguồn dữ liệu cho điều hành CSTT tại các quốc gia cho thấy, có thể phân loại các dữ liệu này theo nhiều cách khác nhau. Một số tiêu thức phân loại điển hình có thể kể đến là phân loại dựa trên sự phát triển của dữ liệu, phân loại dựa trên nguồn thu thập dữ liệu, phân loại dựa trên sự phổ biến và hữu ích của dữ liệu và phân loại dựa trên mục đích sử dụng của dữ liệu.
Casey (2014) phân loại nguồn dữ liệu cho điều hành CSTT thành 02 loại chính: (i) Dữ liệu truyền thống và (ii) Dữ liệu mới. Trong đó, dữ liệu truyền thống bao gồm dữ liệu vĩ mô, dữ liệu khảo sát và dữ liệu từ các tổ chức tài chính. Dữ liệu kiểu mới bao gồm dữ liệu không cấu trúc (báo cáo giám sát, thông tin mạng xã hội…), dữ liệu vi mô và dữ liệu từ bên thứ ba. Học hỏi từ cách phân loại của Casey (2014), Tissot và cộng sự (2015) đề xuất cách phân loại dựa trên nguồn thu thập bao gồm 05 loại: (i) Dữ liệu từ NHTW và các cơ quan thống kê quốc gia; (ii) Dữ liệu từ các cơ quan chính phủ khác; (iii) Dữ liệu từ Internet; (iv) Dữ liệu từ các tổ chức tài chính và (v) Dữ liệu từ phương tiện truyền thông và mạng xã hội. Wibisono và cộng sự (2019) đề xuất cách phân loại thành 04 loại dựa trên sự phổ biến và hữu ích của dữ liệu đối với NHTW: (i) Dữ liệu từ Internet; (ii) Dữ liệu được thương mại hóa; (iii) Dữ liệu từ thị trường tài chính và (iv) Dữ liệu quản lí.
Ngoài ra, có một cách không phổ biến được NHTW Kenya sử dụng là chia nguồn dữ liệu theo mục đích sử dụng dữ liệu: (i) Dữ liệu thống kê tiền tệ; (ii) Dữ liệu thống kê tài chính công; (iii) Dữ liệu thống kê cán cân thanh toán và (iv) Dữ liệu thống kê ngành. Cách phân loại này bộc lộ nhiều hạn chế do việc phân tích các loại dữ liệu dựa trên mục đích sử dụng sẽ không làm rõ được tính chất, đặc điểm của dữ liệu.
Theo đánh giá của tác giả, dù còn bộc lộ một số hạn chế nhất định, cách phân loại của Casey (2014); Tissot và cộng sự (2015); Wibisono và cộng sự (2019) có nhiều điểm chung. Cách phân loại của Casey (2014) khá ưu việt khi phân loại thành kiểu truyền thống và mới, nhưng khi đề cập đến các loại dữ liệu mới các tác giả lại phân loại thành những nhóm không cân bằng nhau. Cách phân loại của Tissot và cộng sự (2015) dựa trên các nguồn thu thập đã khắc phục được hạn chế không cân bằng của Casey (2014), tuy nhiên lại chưa làm nổi bật đến vấn đề “dữ liệu mới” đang được quan tâm trong các NHTW hiện nay. Bên cạnh đó, dữ liệu từ cơ sở dữ liệu của NHTW, từ cơ quan thống kê quốc gia và dữ liệu từ các cơ quan chính phủ khác có đặc điểm tương đối giống nhau. Cách phân loại của Wibisono và cộng sự (2019) đã rút gọn và đơn giản hóa hơn, khái quát được toàn cảnh bức tranh về các nguồn dữ liệu trong điều hành CSTT nhưng cũng chưa đề cập đến vấn đề dữ liệu mới như Tissot và cộng sự (2015). Kế thừa các nghiên cứu đi trước, nghiên cứu này đề xuất cách phân loại như sau: Phân chia dữ liệu thành 02 kiểu dữ liệu truyền thống (bao gồm dữ liệu vĩ mô, dữ liệu khảo sát, dữ liệu từ các tổ chức tài chính) và dữ liệu mới (dữ liệu Internet, dữ liệu thương mại hóa, dữ liệu trên thị trường tài chính và dữ liệu quản lí). Trong đó:
- Dữ liệu vĩ mô: Là dữ liệu cơ bản được thống kê để phản ánh sản lượng của một nền kinh tế, chính phủ hay một khu vực.
- Dữ liệu khảo sát: Là dữ liệu được thu thập được từ khảo sát được thực hiện bởi các tổ chức có uy tín, các cơ quan quản lí nhà nước.
- Dữ liệu từ tổ chức tài chính: Là dữ liệu được thu thập từ báo cáo của các tổ chức tài chính.
- Dữ liệu Internet: Là dữ liệu được thu thập trên Internet với đa dạng các hình thức và nguồn. Ví dụ như lịch sử tìm kiếm, số lần truy cập, thông tin hiển thị và đăng tải.
- Dữ liệu thương mại hóa: Là dữ liệu được cung cấp bởi các tổ chức có uy tín và được cung cấp với mục đích thương mại hóa.
- Dữ liệu thị trường tài chính: Là dữ liệu thu thập từ thị trường tài chính.
- Dữ liệu quản lí: Là dữ liệu thu thập từ các cơ quan quản lí trong lĩnh vực tài chính - ngân hàng. (Hình 1)
Hình 1: Phân loại dữ liệu điều hành CSTT
theo Casey (2014); Wibisono và cộng sự (2019)
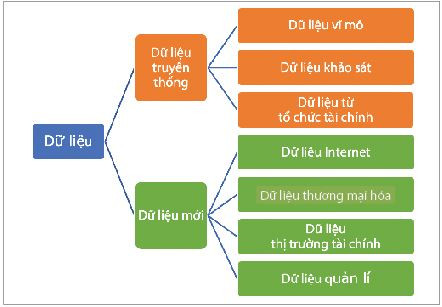
Nguồn: Tổng hợp của nhóm nghiên cứu
3. Kinh nghiệm quốc tế về xây dựng và ứng dụng dữ liệu mới trong điều hành CSTT
3.1. Kinh nghiệm của Hoa Kỳ
3.1.1. Tổng quan các loại dữ liệu mới
Tại Hoa Kỳ, việc quản lí, điều hành CSTT, kinh tế vĩ mô tập trung vào khai thác các nguồn dữ liệu thời gian thực (real - time data), các nguồn dữ liệu hiện đại hơn về bản chất cũng là dữ liệu thời gian thực, nhưng được mở rộng thành dữ liệu lớn nhờ các công cụ, phương pháp thu thập dựa trên công nghệ tiên tiến. Trong những năm gần đây, khi cuộc CMCN 4.0 diễn ra ngày càng mạnh mẽ, việc sử dụng dữ liệu lớn rất cần thiết, đặc biệt là trong việc phân tích, điều hành các chính sách vĩ mô của một quốc gia. Một số nghiên cứu như của Bok và cộng sự (2017); Brave và cộng sự (2019) đã đánh giá việc ứng dụng dữ liệu lớn để quản lí, giám sát các điều kiện kinh tế vĩ mô tại Hoa Kỳ, đồng thời giúp NHTW dự báo thị trường và điều hành CSTT.
Theo Bok và cộng sự (2017), Ủy ban Xác định Niên đại của Cục Nghiên cứu Kinh tế Quốc gia Hoa Kỳ (NBER) tiến hành kiểm tra và so sánh hành vi của nhiều biện pháp hoạt động kinh tế rộng lớn và toàn diện, bằng nguồn dữ liệu chủ yếu là GDP thực tế và gần đây nhất là tổng thu nhập quốc nội thực tế (GDI), các chỉ số thị trường lao động và sản xuất công nghiệp, cùng với các chỉ số khác ít bao quát hơn nhưng mang tính thông tin cao, để xác định khi nào một cuộc suy thoái kinh tế bắt đầu và kết thúc (Bok và cộng sự, 2017). Ngoài ra, tại Hoa Kỳ, việc sử dụng các dữ liệu về dự báo của chuyên gia cũng được khuyến khích. Các dự báo thị trường cũng được thu thập từ các cuộc khảo sát (trong đó cuộc khảo sát được triển khai rộng rãi nhất là của Bloomberg).
Dự báo có vẻ hữu ích nhất khi người ta muốn hiểu nền kinh tế hiện đang ở đâu, nhưng dự đoán hiện tại đòi hỏi phải theo dõi một bộ dữ liệu lớn và phức tạp vì nó liên tục có sẵn trong thời gian thực (Bok và cộng sự, 2017). Trong hai thập kỉ qua, tại Hoa Kỳ, các phương pháp mới trong kinh tế lượng chuỗi thời gian đã giúp phát triển các nền tảng để dự báo thời gian thực, kết hợp các mô hình chính thức cho dữ liệu lớn và được chọn lọc vào dự báo hiện tại của các biến số không thể quan sát trực tiếp hay còn gọi là dự báo tức thời (nowcasting). Đối với GDP, biến số đại diện nhất và được trích dẫn nhiều nhất trong tất cả các biến số kinh tế vĩ mô, Cục Phân tích Kinh tế (BEA) đưa ra các ước tính điểm chuẩn 05 năm một lần dựa trên một cuộc điều tra kinh tế bao gồm gần như tất cả các lĩnh vực, khoảng 7 triệu doanh nghiệp có nhân viên được trả lương ở Hoa Kỳ và hơn 95% các khoản chi được bao gồm trong GDP. Đây có thể coi là một loại dữ liệu kinh tế vô cùng lớn. Các ước tính điểm chuẩn của BEA cung cấp một bức tranh tổng quan, chính xác, toàn diện và chi tiết về nền kinh tế Hoa Kỳ, các ước tính hằng năm và hằng quý dựa trên các cuộc khảo sát cũng do BEA thực hiện, với khoảng 150.000 đơn vị (hằng năm) và 35.000 đơn vị (hằng quý) báo cáo, cũng như trên dữ liệu hành chính (ví dụ từ Sở Thuế vụ) và bằng phép ngoại suy dựa trên các mẫu trong quá khứ hoặc dữ liệu nguồn khác (ví dụ về việc làm, giờ làm việc và thu nhập từ Cục Thống kê Lao động).
Tương tự, những quan điểm của Bok và cộng sự (2017), Brave và cộng sự (2019) cũng áp dụng những kết quả tiến bộ trong các tài liệu gần đây để tạo ra một chỉ số “dữ liệu lớn” mới về hoạt động kinh tế của Hoa Kỳ. Chỉ số được Brave và cộng sự (2019) xây dựng là sự mở rộng của Chỉ số hoạt động quốc gia của Fed Chicago (CFNAI). CFNAI là thước đo tăng trưởng hằng tháng trong hoạt động kinh tế của Hoa Kỳ được xây dựng từ một bảng gồm 85 chuỗi thời gian kinh tế vĩ mô, bao gồm 04 loại hoặc nhóm chỉ số: Sản xuất và thu nhập; việc làm, thất nghiệp và giờ làm; tiêu dùng cá nhân, nhà ở và bán hàng; đơn đặt hàng và hàng tồn kho. Bằng cách bao gồm một bộ chỉ số đa dạng như vậy, chỉ số của Brave và cộng sự (2019) được thiết kế để nắm bắt các chuyển động rộng lớn trong hoạt động kinh tế tổng hợp của Hoa Kỳ xung quanh tốc độ tăng trưởng kinh tế lịch sử dài hạn. Giá trị bằng 0 của chỉ số cho thấy tăng trưởng trong hoạt động kinh tế đang diễn ra với tốc độ trung bình, trong khi giá trị âm biểu thị mức tăng trưởng dưới mức trung bình và giá trị dương biểu thị mức tăng trưởng trên mức trung bình.
3.1.2. Lợi ích của dữ liệu mới đối với điều hành CSTT và kinh tế vĩ mô
Theo Bok và cộng sự (2017), Brave và cộng sự (2019), trạng thái hay chu kì của nền kinh tế Hoa Kỳ đều được xác định và phân tích bằng cách sử dụng nguồn dữ liệu lớn. Bằng cách xem xét kĩ lưỡng hàng trăm chuỗi dữ liệu để tìm kiếm các mẫu và quy luật, sự vận động đồng nhất và có hệ thống của các lĩnh vực và nhiều loại hoạt động kinh tế khác nhau được phát hiện, từ đó xác định được trạng thái của nền kinh tế là phát triển, ổn định hay suy thoái, cũng như xác định được điểm ngoặt của các chu kì kinh tế này (Burns và Mitchell, 1946; Harding và Pagan, 2016).
Ngoài ra, nowcasting là một kĩ thuật khá mới trong hồi quy chuỗi thời gian và nó có khả năng tiếp tục được phát triển trên nhiều mặt. Thứ nhất, việc cùng thiết lập mô hình các điều kiện vĩ mô và tài chính sẽ tạo ra một giao diện giữa tài chính và kinh tế vĩ mô. Điều này sẽ đưa ra một khuôn khổ mạch lạc để nghiên cứu các cơ chế mà thông qua đó tin tức kinh tế vĩ mô được truyền đến thị trường tài chính. Thứ hai, nowcasting có thể được phát triển trong một môi trường cấu trúc, bởi nó sẽ cho phép tính toán các ước tính theo thời gian thực của các biến số không thể quan sát trực tiếp. Việc đọc luồng dữ liệu qua lăng kính của một mô hình cấu trúc cũng sẽ giúp xác định các cú sốc có ý nghĩa đối với nền kinh tế trong thời gian thực.
Cùng với mô hình nowcasting của Bok và cộng sự (2017), chỉ số “dữ liệu lớn” mới của Brave và cộng sự (2019) có thể được sử dụng để theo dõi chu kì kinh doanh và lạm phát của Hoa Kỳ trong thời gian thực và ước tính mức tăng trưởng GDP thực tế hằng tháng. Từ đó, khắc phục khó khăn do độ trễ trong các thước đo toàn diện về hoạt động kinh tế, chẳng hạn như GDP thực tế của Hoa Kỳ, giúp NHTW đưa ra các dự đoán kịp thời về tình trạng hiện tại của nền kinh tế trong quá trình thực hiện CSTT.
3.1.3. Quản trị dữ liệu mới
Tại Hoa Kỳ, việc quản trị dữ liệu nói chung, đặc biệt là dữ liệu lớn được thực hiện dựa trên Chiến lược dữ liệu liên bang Hoa Kỳ. Chiến lược này xác định các nguyên tắc, thông lệ và kế hoạch hành động hằng năm để đưa ra cách tiếp cận nhất quán hơn đối với việc quản lí, sử dụng và truy cập dữ liệu liên bang. Chiến lược dữ liệu liên bang Hoa Kỳ gồm 04 lĩnh vực: Quản trị dữ liệu tổng thể; truy cập, sử dụng và mở rộng; ra quyết định và trách nhiệm; thương mại hóa, đổi mới và sử dụng công cộng. Trong đó, đối với nội dung về “Quản trị dữ liệu tổng thể”, Chiến lược nêu rõ việc “đặt ưu tiên việc quản lí dữ liệu của Chính phủ như một tài sản chiến lược, bao gồm thiết lập chính sách dữ liệu, xác định vai trò và trách nhiệm đối với quyền riêng tư, an ninh và bảo mật dữ liệu, giám sát việc tuân thủ các tiêu chuẩn và chính sách trong suốt vòng đời thông tin” (Phạm Văn Thịnh, 2019).
Đối với riêng các dữ liệu lớn về tài chính, hiện nay Hoa Kỳ vẫn chưa có quy định cụ thể cho việc quản trị các dữ liệu này. Tuy nhiên, nhìn chung, phần lớn dữ liệu này được lưu trữ và quản trị bởi các cơ quan chính phủ như NHTW (Fed), các ngân hàng dự trữ liên bang, BEA, NBER…, dưới dạng các cơ sở dữ liệu lớn có thể truy cập và tiếp cận rộng rãi trên nền tảng Internet. Từ đó, giúp các chuyên gia, nhà nghiên cứu thuận tiện trong việc tổng hợp và xây dựng các chỉ số mới, các nguồn dữ liệu mới hơn cho điều hành kinh tế vĩ mô và CSTT của quốc gia.
3.2. Kinh nghiệm của Trung Quốc
3.2.1. Tổng quan các loại dữ liệu mới
Trong ngành tài chính của Trung Quốc, sự phát triển gắn với dữ liệu lớn được coi là hướng đi trong tương lai. Theo một cuộc khảo sát về các xu hướng do Liên đoàn Máy tính Trung Quốc (CCF) thực hiện, việc sử dụng dữ liệu lớn trong ngành tài chính đứng ở vị trí thứ hai, chỉ sau thương mại điện tử (CCF, 2013a). Quy mô tuyệt đối của nền kinh tế và dân số Trung Quốc cho thấy, đây là một trong số các quốc gia có nguồn cơ sở dữ liệu lớn nhất trên thế giới, nghĩa là có nhiều kênh hơn và khả năng lớn hơn để phát triển và sử dụng dữ liệu lớn (Li và cộng sự, 2014).
Các ngân hàng lớn của Trung Quốc đang chuyển đổi thành các công ty dữ liệu lớn, sử dụng công nghệ khai thác dữ liệu để khám phá giá trị kinh doanh của dữ liệu và phát triển chuỗi giá trị dữ liệu. Ngành tài chính Trung Quốc được quản lí chặt chẽ với tổng tài sản lên đến hơn 150.000 tỉ nhân dân tệ (tương đương 24.000 tỉ USD) và hơn 100 terabyte (TB) (IDC, 2012) gồm cả dữ liệu cấu trúc và phi cấu trúc. Tính đến tháng 3/2014, Ngân hàng Công thương Trung Quốc (ICBC) có hơn 4,9 petabyte (PB) dữ liệu được lưu trữ. Dữ liệu cấu trúc và phi cấu trúc hằng năm của Ngân hàng Nông nghiệp Trung Quốc (ABC) lần lượt là 100 TB và 1 PB (ABC, 2014). Ngân hàng Truyền thông (BOCOM) xử lí khoảng 600 gigabyte (GB) dữ liệu hằng ngày, với dung lượng lưu trữ hơn 70 TB (BOCOM, 2014). Ngoài ra, thị trường chứng khoán Trung Quốc là một trong những thị trường sớm nhất áp dụng giao dịch điện tử và hơn 200 triệu nhà đầu tư hiện tạo ra trung bình hơn 60.000 đơn đặt hàng mỗi phút. Hệ thống trực tuyến của Ủy ban Chứng khoán và Điều tiết Trung Quốc (CSRC) và các sàn giao dịch chứng khoán thực hiện phân tích ngữ nghĩa để phát hiện hơn 100 triệu dữ liệu truyền thông xã hội hằng ngày (SSE, 2014; SZSE, 2013).
Với dữ liệu lớn, các công ty ở mọi cấp độ đều có cơ hội phát triển trong ngành tài chính Trung Quốc. Đặc biệt, các nhà lãnh đạo, quản lí ngành tài chính mong muốn tận dụng triệt để nguồn tài nguyên này để cạnh tranh trên thị trường toàn cầu. Trung tâm Tham chiếu Tín dụng của Ngân hàng Nhân dân Trung Quốc (CRCPBC) thu thập dữ liệu do các ngân hàng thương mại và các cơ quan xã hội khác báo cáo (và được xác minh bởi Trung tâm xác thực danh tính). Tính đến cuối tháng 11/2013, dữ liệu của nó đã đại diện cho hơn 830 triệu cá nhân và gần 20 triệu doanh nghiệp hoặc tổ chức khác; trong số này, khoảng 300 triệu người có hồ sơ vay nợ ở ngân hàng hoặc tổ chức tài chính khác (CRCPBC, 2013).
3.2.2. Lợi ích của dữ liệu mới đối với điều hành CSTT và kinh tế vĩ mô
Chính phủ Trung Quốc đã thể hiện sự quan tâm và hỗ trợ lớn đối với việc phát triển và sử dụng sáng tạo dữ liệu lớn trong ngành tài chính. Báo cáo Công việc của Chính phủ Trung Quốc đề xuất rằng, dữ liệu lớn là ngành công nghiệp hàng đầu trong phát triển kinh tế quốc gia của đất nước (Li, 2014). CCF cho rằng, dữ liệu lớn có tác động sâu sắc đến hai mối quan tâm chính của ngành tài chính Trung Quốc là rủi ro và tín dụng (CCF, 2013b). Khai thác dữ liệu sâu và phân tích giá trị dựa trên dữ liệu lớn có thể nâng cao khả năng quản lí rủi ro tài chính. Những dữ liệu được thu thập về các đối tượng vay nợ tại ngân hàng giúp Ngân hàng Nhân dân Trung Quốc xây dựng hệ thống tín dụng một cách hoàn chỉnh và có thể được công chúng tiếp cận, góp phần to lớn vào tính minh bạch và tính sẵn có của thông tin tín dụng.
Theo Du (2021), trong một số lĩnh vực cụ thể, phân tích thống kê dữ liệu lớn có thể dự đoán xu hướng phát triển kinh tế trong tương lai của Trung Quốc. Công việc phân tích thống kê dữ liệu lớn được xử lí bởi mô hình dữ liệu và các quy tắc phát triển kinh tế vĩ mô có thể được làm rõ với sự trợ giúp của tin học hóa. Do đó, sự ra đời của phương pháp phân tích dữ liệu lớn cung cấp cơ sở cố định cho phân tích kinh tế vĩ mô. Việc ứng dụng thống kê dữ liệu lớn có thể phản ánh chân thực sự phát triển kinh tế, đặc biệt là trong phân tích các hoạt động kinh tế - xã hội. Chính phủ có thể đưa ra những kết luận khách quan hơn thông qua kết quả phân tích thống kê dữ liệu lớn, từ đó giúp Chính phủ điều hành vĩ mô và thúc đẩy hiệu quả sự phát triển của các ngành dịch vụ của Chính phủ.
3.2.3. Quản trị dữ liệu mới
Hàng loạt văn bản pháp luật đã được Trung Quốc ban hành nhằm xây dựng các tiêu chuẩn mới trong việc quản lí nguồn dữ liệu ngày càng nhiều và phức tạp, trong đó có 03 văn bản quan trọng là Luật An ninh mạng (2017), Luật Bảo mật dữ liệu (2021), Luật Bảo vệ thông tin cá nhân (2022). Đồng thời, khi vai trò của dữ liệu lớn trong thế giới kinh tế và tài chính tăng lên, điều quan trọng đối với Trung Quốc là cải thiện các hệ thống phân tích dữ liệu và củng cố tính bảo mật của các mạng lưới tài chính. Tập đoàn Huawei đã giúp Cơ quan Quản lí Ngoại hối Nhà nước (SAFE) sử dụng công nghệ ảo hóa (virtualization) để bảo vệ dữ liệu và tăng cường sự ổn định của doanh nghiệp (Li và cộng sự, 2014). Theo số liệu thống kê, Trung Quốc đã triển khai 10 cụm trung tâm dữ liệu quốc gia để lưu trữ từ xa lượng lớn dữ liệu và lưu trữ các dịch vụ điện toán đám mây, cho phép thuê, mua hoặc bán phần mềm và các tài nguyên số khác theo yêu cầu. Các trung tâm dữ liệu quốc gia là những cơ sở an toàn, có kiểm soát nhiệt độ và được xây dựng để đặt các máy chủ công suất lớn, hệ thống lưu trữ dữ liệu, nhiều nguồn điện và kết nối Internet băng thông cao (Văn Khoa, 2022).
3.3. Kinh nghiệm của Ý
3.3.1. Tổng quan các loại dữ liệu mới
Tại Ý, NHTW Ý chịu trách nhiệm xây dựng và thực thi CSTT phù hợp với mục tiêu ổn định giá cả và một số mục tiêu khác của NHTW Châu Âu (ECB). Là thành viên của Liên minh châu Âu (EU) và Khu vực đồng tiền chung châu Âu, Ý tham gia vào khuôn khổ CSTT của ECB - cơ quan đặt ra các mục tiêu về tỉ lệ lạm phát và điều chỉnh lãi suất, bên cạnh các cơ chế khác. Khung chính sách này nhằm đảm bảo ổn định giá cả trên toàn EU, đồng thời hỗ trợ các mục tiêu cao hơn như tăng trưởng và ổn định kinh tế.
Những năm gần đây, NHTW Ý đã khai thác dữ liệu lớn và các công nghệ liên quan để nâng cao hiệu lực và hiệu quả của CSTT. Các ứng dụng nổi bật về dữ liệu lớn trong quản lí CSTT của Ý bao gồm:
(1) Giám sát hệ thống thanh toán: Dữ liệu này được sử dụng để cung cấp thông tin cho các quyết định của NHTW về quản trị thanh khoản, quy định và can thiệp chính sách. NHTW Ý đã phát triển nhiều hệ thống khác nhau để giám sát hoạt động của hệ thống thanh toán theo thời gian thực, chẳng hạn như Hệ thống thanh toán liên kết liên tục (CLSS), tạo điều kiện cho việc tất toán các khoản vay liên ngân hàng giá trị lớn giữa các ngân hàng Ý và các đối tác quốc tế (Bank of Italy, 2021).
(2) Dự báo kinh tế vĩ mô: Về hoạt động dự báo vĩ mô, NHTW Ý phối hợp chặt chẽ với NHTW và cơ quan thống kê các nước thành viên EU trong việc tận dụng các công nghệ dữ liệu lớn (ví dụ như học máy và trí tuệ nhân tạo) để phân tích các tập dữ liệu lớn về các chỉ số vĩ mô, dữ liệu thị trường tài chính, tâm lí truyền thông xã hội và các nguồn dữ liệu phi cấu trúc khác (Bank of Italy, 2020). Dữ liệu đầu vào này được sử dụng cho việc phát triển các mô hình dự báo kinh tế hiện đại và phức tạp nhằm hỗ trợ có hiệu quả cho các quyết định CSTT.
(3) Giám sát tuân thủ: Để giám sát hiệu quả việc tuân thủ các quy định trong lĩnh vực tiền tệ - ngân hàng, NHTW Ý dựa trên phân tích dữ liệu lớn để nhận diện các hành vi vi phạm tiềm ẩn, chẳng hạn như rửa tiền, gian lận và giao dịch nội gián. NHTW đã phát triển nhiều hệ thống khác nhau sử dụng dữ liệu lớn và trí tuệ nhân tạo để giám sát các hoạt động thị trường và xác định các mô hình bất thường có thể cần điều tra bổ sung.
(4) Giám sát ổn định tài chính: Công nghệ dữ liệu lớn và trí tuệ nhân tạo được tận dụng để phân tích tập dữ liệu lớn về thị trường tài chính, các chỉ số rủi ro hệ thống và các biến số vĩ mô để có thể đưa ra các đánh giá ổn định tài chính kịp thời và hữu hiệu. Các đánh giá này được sử dụng để xác định các "lỗ hổng" tiềm ẩn trong hệ thống tài chính, chẳng hạn như sử dụng đòn bẩy quá mức hoặc bong bóng giá tài sản, đồng thời cung cấp thông tin nhằm xác lập các biện pháp can thiệp nhằm giảm thiểu rủi ro từ phía NHTW (Schwartz, 2021).
(5) Phát hiện và ngăn chặn gian lận: NHTW Ý dựa vào dữ liệu lớn và công nghệ trí tuệ nhân tạo để phân tích các bộ dữ liệu lớn về hành vi của khách hàng, dữ liệu giao dịch và các chỉ số khác về khả năng gian lận. Dữ liệu đầu vào này được sử dụng để phát triển mô hình máy học có thể xác định những xu hướng bất thường và phát hiện hành vi gian lận tiềm ẩn trong thời gian thực. Việc điều tra và truy tố các trường hợp gian lận được thực hiện dựa trên sự hợp tác giữa NHTW Ý, cơ quan thực thi pháp luật và cơ quan quản lí có liên quan (Bank of Italy, 2020).
3.3.2. Lợi ích của dữ liệu mới đối với điều hành CSTT và kinh tế vĩ mô
Việc áp dụng trên diện rộng các dạng dữ liệu mới trong công tác điều hành CSTT và vĩ mô tại Ý mang tới các lợi ích sau:
(1) Tạo thuận lợi cho việc thu thập, phân tích dữ liệu: Với sự phát triển của dữ liệu lớn, các NHTW hiện nay có quyền truy cập vào vô số dữ liệu thời gian thực. Các dữ liệu này có thể được sử dụng để theo dõi các chỉ số kinh tế và đưa ra các quyết định sáng suốt.
(2) Hỗ trợ hiệu quả cho việc ra quyết định CSTT: NHTW Ý giờ đây có thể sử dụng các kĩ thuật lập mô hình phức tạp để phân tích trường dữ liệu lớn một cách nhanh chóng. Do đó, các NHTW có thể đưa ra quyết định sáng suốt hơn dựa trên các phân tích dữ liệu đầy đủ và chính xác.
(3) Cải thiện năng lực dự báo vĩ mô: Bằng cách phân tích dữ liệu thời gian thực, NHTW Ý có thể đoán định những thay đổi trong hoạt động kinh tế chính xác hơn. Điều này có thể giúp NHTW điều chỉnh CSTT một cách hiệu quả để hỗ trợ tăng trưởng kinh tế ổn định.
(4) Am hiểu về hành vi người tiêu dùng: Dữ liệu lớn cũng có thể cung cấp thông tin chi tiết về hành vi của người tiêu dùng. Nhờ theo dõi xu hướng chi tiêu của người tiêu dùng, NHTW Ý có những động thái điều chỉnh quyết sách cần thiết nhằm bổ trợ cho các mục tiêu phát triển nói chung.
(5) Cải thiện đánh giá rủi ro: Bằng cách phân tích dữ liệu thời gian thực, NHTW Ý có thể nhanh chóng xác định các lĩnh vực rủi ro tiềm ẩn trong nền kinh tế. Điều này cho phép họ thực hiện biện pháp chủ động để giảm tác động của các cú sốc kinh tế.
3.3.3. Quản trị dữ liệu mới
Hạ tầng quản trị dữ liệu lớn của NHTW Ý được thiết kế theo 03 lớp: Hồ dữ liệu, lớp xử lí và lớp phân tích dữ liệu. Hồ dữ liệu lưu trữ tất cả dữ liệu có cấu trúc và phi cấu trúc trong một kho lưu trữ tập trung, trong khi lớp xử lí thực hiện các hoạt động như tính toán, chuyển đổi, làm sạch và tổng hợp dữ liệu. Tại lớp phân tích, các truy vấn, phân tích được tiến hành nhằm cung cấp thông tin phục vụ việc ra quyết sách của lãnh đạo NHTW (Yaghoubi và Badi, 2019). Với việc tách bạch các lớp chức năng như trên, chất lượng dữ liệu có thể được cải thiện đáng kể thông qua việc giảm thiểu sai sót, bất nhất và tăng cường tính quy chuẩn ở từng giai đoạn tác vụ (Anjum và cộng sự, 2017).
3.4. Kinh nghiệm của Nhật Bản
3.4.1. Tổng quan các loại dữ liệu mới
Trải qua chu kì lạm phát thấp và kéo dài, các công cụ CSTT truyền thống tại Nhật Bản không còn quá hữu dụng. Do đó, Nhật Bản đã thử nghiệm các công cụ CSTT độc đáo, chẳng hạn như nới lỏng định lượng và kiểm soát đường cong lợi suất để quản lí CSTT. Tuy nhiên, sau một thời gian triển khai, các công cụ phi truyền thống này bắt đầu bộc lộ những hạn chế, đòi hỏi NHTW Nhật Bản (Bank of Japan - BOJ) phải tiếp tục tìm ra những giải pháp mới để thích ứng với điều kiện hiện hữu của nền kinh tế. Một trong những giải pháp khả thi, theo Toyoda và cộng sự (2019), là sử dụng phân tích dữ liệu lớn.
Một trong những nguồn dữ liệu nổi bật được sử dụng cho việc điều hành chính sách là dữ liệu di động. BOJ đã và đang sử dụng dữ liệu di động để theo dõi giá tiêu dùng, tuyến vận chuyển và hành vi người tiêu dùng... Ngoài ra, BOJ cũng sử dụng dữ liệu truyền thông xã hội để nắm bắt tâm lí người tiêu dùng và dữ liệu ngân hàng để theo dõi xu hướng thanh toán và cho vay. Về hạ tầng công nghệ, BOJ đã thành lập một trung tâm nghiên cứu về dữ liệu lớn dựa trên sự hợp tác với các công ty công nghệ hàng đầu để phát triển các phương pháp và công cụ phân tích mới (Brettschneider và cộng sự, 2019).
Một trong những công cụ CSTT độc đáo được sử dụng ở Nhật Bản là kiểm soát đường cong lợi suất. BOJ đặt mục tiêu kiểm soát đường cong lợi suất bằng cách hướng lợi suất trái phiếu Chính phủ (JGB) kì hạn 10 năm về mức 0%. Trên thực tế, việc kiểm soát đường cong lợi suất đã làm gia tăng hiệu quả trong việc điều tiết đường cong lợi suất, song nó đòi hỏi phải liên tục theo sát diễn biến các chỉ số kinh tế khác nhau. Để hỗ trợ công cụ kiểm soát đường cong lợi suất, BOJ đã sử dụng các thuật toán học máy để dự đoán những thay đổi và cải thiện độ chính xác trong đường cong lợi suất. Bên cạnh đó, dữ liệu di động và tuyến vận chuyển cũng được tận dụng để giám sát các hoạt động kinh tế (Kuroda, 2019).
3.4.2. Lợi ích của dữ liệu mới đối với điều hành CSTT và kinh tế vĩ mô
Việc áp dụng trên diện rộng các dạng dữ liệu mới trong công tác điều hành CSTT và vĩ mô tại Nhật Bản mang tới các lợi ích sau:
(1) Cải thiện chất lượng các quyết sách: BOJ đã thu thập một lượng lớn dữ liệu liên quan đến hoạt động kinh tế, giá cả và thị trường tài chính trong nhiều năm. Điều này được thực hiện nhờ những tiến bộ trong công nghệ cho phép sử dụng các công cụ thu thập dữ liệu phức tạp hơn. Cơ sở dữ liệu phong phú và đa dạng này đã cải thiện đáng kể hiệu quả của các mô hình dự báo vĩ mô, theo đó định hướng cho các quyết sách của BOJ (Borio và Shim, 2017).
(2) Phân tích dữ liệu thời gian thực: Bằng cách sử dụng các công cụ số mới nhất, dữ liệu lớn cho phép phân tích thời gian thực các chỉ số kinh tế, xu hướng thị trường và hành vi của người tiêu dùng, cho phép BOJ phát hiện các xu hướng quan trọng và đề xuất các phản ứng chính sách. Việc sử dụng phân tích dữ liệu thời gian thực đặc biệt có giá trị trong thời kì kinh tế bất ổn hoặc khi đối phó với những thay đổi nhanh chóng trong nền kinh tế (Brettschneider và cộng sự, 2019).
(3) Cải thiện mô hình kinh tế: Bằng cách cho phép tích hợp dữ liệu diện rộng vào các mô hình kinh tế truyền thống, dữ liệu lớn có thể giúp các nhà hoạch định có được cái nhìn thực tế hơn về nền kinh tế. Theo đó, các nhà hoạch định có thể ước tính các mô hình truyền thống theo thời gian thực, cải thiện độ chính xác của kết quả (Borio và Shim, 2017).
3.4.3. Quản trị dữ liệu mới
BOJ có sẵn một cấu trúc quản trị dữ liệu mạnh để đảm bảo tính chính xác, toàn vẹn và bảo mật của dữ liệu. Vai trò của quản trị dữ liệu được đặc biệt nhấn mạnh để đảm bảo dữ liệu được quản lí dựa trên việc tuân thủ các yêu cầu pháp lí và đạo đức (BOJ, 2017). Theo đó, BOJ thiết lập một khung quản lí dữ liệu dựa trên các tiêu chuẩn ngành và thông lệ quốc tế tốt nhất. Khung này bao gồm toàn bộ vòng đời dữ liệu, từ thu thập, xử lí dữ liệu đến lưu trữ dữ liệu. Khuôn khổ này thường xuyên được rà soát, cập nhật để đảm bảo sự phù hợp và hiệu quả. BOJ cũng có một ủy ban quản trị dữ liệu, giám sát việc thực hiện khuôn khổ quản lí dữ liệu.
(1) Thu thập, xử lí dữ liệu: BOJ thu thập một lượng lớn dữ liệu từ nhiều nguồn khác nhau, bao gồm các tổ chức tài chính, cơ quan chính phủ và các tổ chức quốc tế như Quỹ Tiền tệ Quốc tế (IMF). Dữ liệu được thu thập bao gồm thông tin về các chỉ số kinh tế, giao dịch tài chính, CSTT, dự trữ ngoại hối và hệ thống thanh toán.
(2) Quản trị và xử lí dữ liệu: BOJ sử dụng các hệ thống và công cụ khác nhau, bao gồm kho dữ liệu riêng được xây dựng trên nền tảng Oracle, khung xử lí dữ liệu nguồn mở Hadoop và các ngôn ngữ lập trình như Python, R. BOJ cũng sử dụng trí tuệ nhân tạo và kĩ thuật học máy để phân tích dữ liệu và đưa ra các phán đoán.
(3) Lưu trữ và truy xuất dữ liệu: BOJ có một hệ thống kho lưu trữ dữ liệu hiện đại và an toàn để quản lí lượng dữ liệu khổng lồ thu thập được. Cụ thể, BOJ sử dụng kết hợp các giải pháp tại chỗ và dựa trên đám mây để đảm bảo dữ liệu có thể được truy cập nhanh chóng và hiệu quả từ mọi nơi. BOJ cũng sử dụng các công nghệ nén dữ liệu tiên tiến để giảm dung lượng lưu trữ cần thiết cho dữ liệu của mình.
(4) Quyền riêng tư và bảo mật dữ liệu: BOJ đã thực hiện một loạt các biện pháp bảo mật để bảo vệ dữ liệu của mình, bao gồm các giao thức truyền dữ liệu an toàn, tường lửa và các hệ thống phát hiện và ngăn chặn xâm nhập. Ngoài ra, BOJ có các chính sách nghiêm ngặt để đảm bảo tính bảo mật của dữ liệu. Quyền truy cập dữ liệu chỉ được giới hạn ở những người được ủy quyền và tất cả quyền truy cập dữ liệu đều được ghi lại và theo dõi. BOJ cũng có sẵn kế hoạch khắc phục thảm họa/sự cố mất an toàn trong trường hợp xảy ra thảm họa tự nhiên hoặc sự kiện thảm khốc khác.
4. Hàm ý dành cho Việt Nam
Trên cơ sở nghiên cứu thực tiễn tại các quốc gia sở hữu nền tảng dữ liệu và công nghệ hàng đầu là Hoa Kỳ, Trung Quốc, Ý và Nhật Bản, tác giả rút ra một số hàm ý dành cho Việt Nam trong việc xây dựng, triển khai và quản lí nguồn dữ liệu mới phục vụ điều hành CSTT:
Thứ nhất, Chính phủ Việt Nam, thông qua các quyết sách định hướng điều hành, cần nhấn mạnh tầm quan trọng của dữ liệu lớn và các nền tảng công nghệ hỗ trợ trong hoạt động phân tích, đánh giá, dự báo và điều hành vĩ mô. Song song với việc định hướng, Chính phủ cần hỗ trợ mạnh mẽ sự phát triển của dữ liệu lớn từ hệ thống luật pháp, chính sách, quy định và chú ý hơn đến bảo mật dữ liệu. Chính phủ cũng cần tích cực khuyến khích các tổ chức, doanh nghiệp xây dựng một môi trường lành mạnh và hiệu quả nhằm phù hợp với sự phát triển của dữ liệu lớn, đồng thời khuyến khích các tổ chức, doanh nghiệp tăng cường ứng dụng công nghệ dữ liệu lớn trong hoạt động kinh doanh. Lí giải cho hàm ý này, nghiên cứu kinh nghiệm các nước đã chỉ ra rằng, công nghệ gắn với dữ liệu lớn trong những năm gần đây đã có những đóng góp vượt bậc đối với hoạt động phân tích kinh tế vĩ mô, giúp cải thiện nguồn thông tin và làm cho việc thu thập dữ liệu toàn diện hơn để nâng cao tính đúng đắn của phân tích kinh tế.
Thứ hai, có thể xem xét thành lập một bộ phận chuyên biệt về thống kê, phân tích kinh tế vĩ mô quốc gia thuộc Tổng cục Thống kê (Bộ Kế hoạch và Đầu tư) hoặc NHNN. Bộ phận này nên mở rộng các kênh, loại hình thu thập dữ liệu và tăng cường thu thập, lưu trữ, bảo vệ và quản lí dữ liệu liên quan để nâng cao mức độ dịch vụ và chất lượng thống kê. Đồng thời, nên chú trọng cải tiến và có những bước đi đột phá trong quản lí dữ liệu, song song với việc thúc đẩy hệ thống, quy trình và phương pháp thống kê dữ liệu.
Thứ ba, ở cấp độ cơ quan quản lí chuyên trách, cần tăng cường mở rộng, khai thác và sử dụng nguồn dữ liệu thời gian thực trong việc phân tích và dự báo kinh tế vĩ mô, bởi đây là nguồn dữ liệu phản ánh chính xác và kịp thời nhất những thay đổi, biến động của nền kinh tế. Cụ thể, NHNN cần tích cực thu thập các dữ liệu thời gian thực bằng cách trực tiếp quan sát, tổng hợp những thay đổi hiện tại của ngành tài chính - ngân hàng, đồng thời kết hợp với những cơ sở dữ liệu sẵn có từ các đơn vị khác như Tổng cục Thống kê, Bộ Tài chính, sàn giao dịch chứng khoán… để thuận tiện cho việc đánh giá thực trạng CSTT của quốc gia và đưa ra kế hoạch điều chỉnh chính sách này trong thời gian tới.
Thứ tư, các đơn vị thống kê thuộc cơ quan quản lí chuyên trách nên chú ý hơn đến việc đào tạo các chuyên gia phân tích dữ liệu lớn, đặc biệt là trong lĩnh vực tài chính - ngân hàng, kinh tế vĩ mô. Ví dụ, việc đào tạo các chuyên gia liên ngành không chỉ đòi hỏi kĩ năng vận hành máy tính chuyên nghiệp mà còn cả khả năng phân tích kinh tế vĩ mô. Do đó, nên tiến hành đào tạo thường xuyên và chú ý nâng cao khả năng phân tích tài chính, kinh tế vĩ mô tổng thể, nên xây dựng đội ngũ phân tích có năng lực cao để đảm bảo đạt hiệu quả cao trong phân tích tài chính, kinh tế vĩ mô trong kỉ nguyên dữ liệu lớn.
Thứ năm, cần đặc biệt quan tâm và có những giải pháp đảm bảo tốt tính bảo mật, xác thực và độ tin cậy của nguồn thông tin, dữ liệu có giá trị cao trong điều hành chính sách. Các cơ quan an toàn thông tin và dữ liệu cần triển khai công tác giám sát về bảo mật dữ liệu kịp thời, chính xác. Trước hết, cần bám sát thực tế, tận dụng triệt để công nghệ thông tin mạng, không ngừng mở rộng các kênh thu thập, tích hợp thông tin trong quá trình tổng hợp thông tin, thống kê dữ liệu kinh tế vĩ mô. Ngoài ra, cần hình thành hệ thống giám sát dữ liệu toàn diện, kiểm soát chặt chẽ việc bảo quản, sử dụng dữ liệu thông tin, bảo đảm an toàn dữ liệu thông tin theo đúng quy trình công việc thực tế. Cần thực hiện quản lí và kiểm soát thống nhất, thực hiện quản lí bí mật đối với một số dữ liệu thông tin đặc biệt và nâng cao toàn diện tính bảo mật của giám sát dữ liệu thông tin.
1 Trong vòng 10 năm kể từ năm 2010 - 2020 có 03 Thông tư mới và 02 Thông tư chỉnh sửa, bổ sung được ban hành liên quan đến chế độ báo cáo.
Tài liệu tham khảo:
1. Agricultural Bank of China (ABC) (2014). Annual Report of ABC 2013. Available at www.abchina.com/en/investor-relations/performance-reports/annual-reports.
2. Altavilla, C., Giannone, D. & Modugno, M. (2014). Low Frequency Effects of Macroeconomic News on Government Bond Yields. Finance and Economics Discussion Series 2014-52, Board of Governors of the Federal Reserve System, June.
3. Anjum, A., Shah, A.A. & Khan, A. (2017). Impact of Big Data Technologies on Management of Financial Institutions. Journal of Finance & Accounting Research, 1(2), pages 21-31.
4. Bank of Italy (2020). Economic Bulletin No.3. Retrieved from https://www.bancaditalia.it/pubblicazioni/bollettino-economico/2020-0030/index.html?com.dotmarketing.htmlpage.language=1
5. Bank of Italy (2021). Payment Systems. Retrieved from https://www.bancaditalia.it/en/servizi-e-funzioni/pagamenti-sistemi/pagamenti/index.html
6. Bank of Japan (BOJ) (2017). Framework for Data Management. Retrieved from https://www.BOJ.or.jp/en/about/guide/data/fram.htm/
7. Bartolini, L., Goldberg, L.S. & Sacarny, A. (2008). How economic news moves markets.
8. Bok, B., Caratelli, D., Giannone, D., Sbordone, A. & Tambalotti, A. (2017). Macroeconomic Nowcasting and Forecasting with Big Data. Staff Reports, Federal Reserve Bank of New York.
9. Borio, C.E. & Shim, I. (2017). What can (macro)-prudential policy do to support monetary policy?. BIS Working Papers, 643.
10. Brave, S.A., Butters, R.A. & Kelley, D. (2019). A new “big data” index of U.S. economic activity. Economic Perspectives, 1. Federal Reserve Bank of Chicago.
11. Brettschneider, C., Himmelberg, C. P. & Schmeling, M. (2019). Big Data Sentiment and Financial Markets: Evidence from the Bank of Japan. Journal of Financial & Quantitative Analysis, 54(2), pages 773-807.
12. Burns, A.F. & Mitchell, W.C. (1946). Measuring Business Cycles. NBER Book Series Studies in Business Cycles.
13. Casey, M. (2014). Emerging opportunities and challenges with central bank data. In the 7th ECB Statistics Conference.
14. China Computer Federation (CCF) (2013a). Predictions of Big Data Trends 2014. Available at www.ccf.org.cn/sites/ccf/zlcontnry.jsp?contentId=2779286443623.
15. China Computer Federation (CCF) (2013b). China Big Data Technology and Industrial Development White Paper. Available at www.ccf.org.cn/sites/ccf/ccfziliao.jsp?contentId=2774793649105.
16. Cornelli, G., Doerr, S., Gambacorta, L. & Tissot, B. (2022). Big data in Asian central banks. Asian Economic Policy Review, 17(2), pages 255-269.
17. Credit Reference Center of the People’s Bank of China (CRCPBC) (2013). Introduction of CRCPBC. Beijing. Available at www.pbccrc.org.cn/zxzx/zxgk/gywm.shtml.
18. Du, M. (2021). Research on the Application of Big Data Statistics in the Field of Economic Management. In E3S Web of Conferences (Vol. 253, p. 02037). EDP Sciences.
19. Gurkaynak, R.S. & Wright, J.H. (2013). Identification and Inference Using Event Studies. Manchester School, 81(9), pages 48-65.
20. Gurkaynak, R.S., Sack, B. & Swanson, E. (2005). The Sensitivity of Long-Term Interest Rates to Economic News: Evidence and Implications for Macroeconomic Models. American Economic Review, 95 (1), pages 425-436.
21. Harding, D. & Pagan, A. (2016). The Econometric Analysis of Recurrent Events in Macroeconomics and Finance. Econometric and Tinbergen Institutes Lectures, Princeton University Press.
22. International Data Corporation (IDC) (2012). Chinese Big Data Technology and Services Market Forecast and Analysis 2012 - 2016. Available at www.idc.com.cn/uploadpic/5-Frank-banking2013.pdf
23. Kuroda, H. (2019). The BOJ’s Yield Curve Control: Framework and Performance. Journal of Economic Perspectives, 33(3), pages 3-26.
24. Li K. (2014). Report on the Work of the Government 2014. Available at http://news.xinhuanet.com/english/special/2014-03/14/c_133187027.htm
25. Li, J., Zhang, W., Wu, D.S. & Zhang, W. (2014). Impacts of big data in the Chinese financial industry. The Bridge, 44(4), pages 20-26.
26. Nymand-Andersen, P. & Pantelidis, E. (2018). Google econometrics: nowcasting euro area car sales and big data quality requirements. ECB Statistics Paper, 30.
27. Schwartz, R. (2021). How Big Data and AI are Transforming Central Banking. Speech at the Central Banking Forum. London, UK.
28. Shanghai Stock Exchange (SSE) (2013). Statistical Yearbook of the Shanghai Stock Exchange. Available at www.sse.com.cn/researchpublications/publication/yearly/c/tjnj_2013.pdf
29. Shenzhen Stock Exchange (SZSE) (2013). Statistical Yearbook of the Shenzhen Stock Exchange. Available at www.szse.cn/main/files/2013/05/28/101380619096.pdf
30. Tissot, B., Hülagü, T., Nymand-Andersen, P. & Suarez, L.C. (2015). Central banks’ use of and interest in big data. Bank for International Settlements.
31. Tomar, L., Guicheney, W., Kyarisiima, H., Zimani, T., Roseth, B. & Acevedo, S. (2016). Big Data in the Public Sector. Inter-Amercian Development Bank.
32. Toyoda, M., Fujiki, H., & Teranishi, Y. (2019). The Bank of Japan’s Monetary Policy, Credibility, and Uncertainty. Springer.
33. Wibisono, O., Ari, H.D., Widjanarti, A., Zulen, A.A. & Tissot, B. (2019). The use of big data analytics and artificial intelligence in central banking. IFC Bulletins, Bank for International Settlements.
34. Yaghoubi, R. & Badi, L.M. (2019). Big data analytics for cyber security: A review of major trends. Computers & Security, 20(7), pages 1-21.
35. Zhu, H. (2014). The impact of big data era on statistics teaching of undergraduate economics and management and countermeasures. Higher Education Research (Chengdu), 31(3), pages 35-37.
36. Tô Huy Vũ (2016). Dữ liệu thống kê tiền tệ chi tiết trong hoạch định CSTT của NHTW.
37. Phạm Văn Thịnh (2019). Quản trị dữ liệu tổng thể trong Chiến lược dữ liệu liên bang Hoa Kỳ. Cục Chuyển đổi số Quốc gia, Bộ Thông tin & Truyền thông. Truy cập từ https://aita.gov.vn/quan-tri-du-lieu-tong-the-trong-chien-luoc-du-lieu-lien-bang-hoa-kỳ
38. Văn Khoa (2022). Trung Quốc phát triển mạnh các trung tâm dữ liệu siêu lớn. Truy cập từ: https://www.vietnamplus.vn/trung-quoc-phat-trien-manh-cac-trung-tam-du-lieu-sieu-lon/806255.vnp
TS. Phạm Đức Anh, ThS. Lê Thị Hương Trà
Học viện Ngân hàng
Học viện Ngân hàng